使用 KFServing 对 AI 模型进行操作化、扩展和注入信任
KFServing 0.5 博客文章
作者:Animesh Singh 和 Dan Sun
输入贡献者:KFServing WG,包括 Yuzhui Liu, Tommy Li, Paul Vaneck, Andrew Butler, Srinivasan Parthasarathy 等。
机器学习已成为各行各业和组织中的关键技术。机器学习领域的一个关键方面是越来越多的模型被生产出来,但它们真的得到部署了吗?如果它们确实得到了部署,是否有足够强大的运维机制来理解模型预测,并监测漂移、准确性、异常、偏差等?在生产环境中部署模型的一个关键方面是能够监测各种指标的预测结果,解释模型做出的决策,并生成质量指标,这在金融、医疗、政府等受监管行业尤为重要。此外,基于这些指标,我们是否有相应的技术来理解这些指标并采取纠正措施,例如进行金丝雀发布?
KFServing 是一个起源于 Kubeflow 社区的项目,它一直在努力解决生产模型服务用例,为 Tensorflow、XGBoost、ScikitLearn、PyTorch 和 ONNX 等常见 ML 框架提供高性能、高抽象度的接口。它封装了自动扩缩、网络、健康检查和服务器配置的复杂性,为模型部署带来了 GPU 自动扩缩、零扩缩容和金丝雀发布等前沿服务功能。我们刚刚发布了 KFServing v0.5 版本,其中包含其他各种功能,以满足模型运维和信任的需求。此外,团队一直在努力通过与各种行业领先技术集成,将 AI 可解释性作为已部署模型的核心组成部分。
KFServing Beta API 和 V2(下一代)推理协议
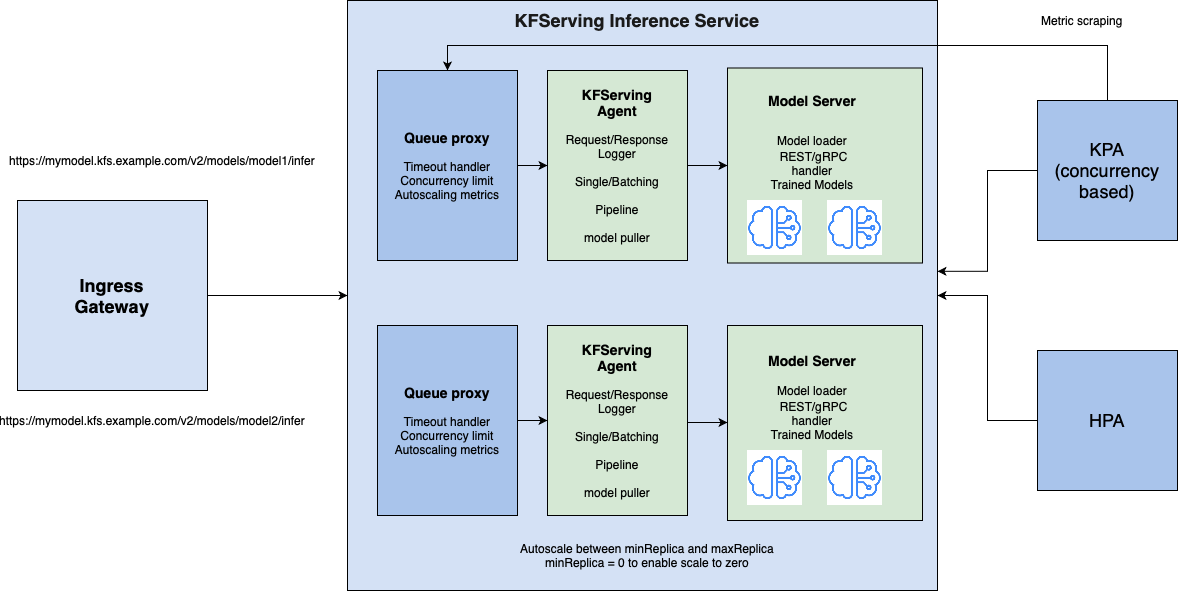
KFServing 0.5 已将控制平面 API 从 v1alpha2 升级到稳定的 v1beta1,并开始支持数据平面V2 推理协议。v1beta1 控制平面 API 提供了简单、对数据科学家友好的接口,同时为预打包的模型服务器提供了指定容器和 pod 模板字段的灵活性。V2 推理协议在 Triton 和 MLServer 等多个模型服务器上推广了标准易用的高性能 REST/gRPC API,以提高模型的便携性,确保客户端/服务器能够无缝运行。
KFServing 0.5 还引入了一个可选的模型代理,用于请求/响应日志记录、请求批处理和模型拉取。模型代理作为边车(sidecar)与模型服务器一同运行。集成到 KFServing 中的预打包模型服务器以及使用自定义框架构建的模型服务器都可以从这些通用的模型服务功能中受益。
新增功能?
-
TorchServe 集成:TorchServe 现在被用作 KFServing PyTorch 模型服务器的实现,它还通过 Captum 实现了模型可解释性,请参阅 TorchServe 示例此处。
-
支持 Triton Inference Server V2 推理 REST/gRPC 协议,请参阅在 GPU 上服务 BERT 和 TorchScript 模型的示例。
-
Tensorflow gRPC 支持。
-
您现在可以在预打包的模型服务器上指定容器或 pod 模板级别的字段(例如,环境变量,readiness/liveness 探针)。
-
允许在组件规范中指定超时。
-
简化金丝雀发布,您不再需要在 InferenceService 规范中同时指定默认和金丝雀规范;KFServing 现在自动跟踪上次发布的版本,并自动在最新的就绪版本和上次发布的版本之间分流流量。
-
Transformer 到 Predictor 的调用现在默认使用 AsyncIO,这显著提高了高并发工作负载场景的延迟/吞吐量。
KFServing 多模型服务实现大规模可伸缩性
随着机器学习方法在组织中得到更广泛的应用,部署大量模型已成为一种趋势。KFServing 的最初设计是每个 InferenceService 部署一个模型。但是,当处理大量模型时,其“一个模型,一个服务器”的范例在 Kubernetes 集群上部署数十万个模型时会带来挑战。为了扩展模型的数量,我们必须扩展 InferenceService 的数量,这会很快挑战集群的极限。
多模型服务是 0.5 版本中添加的 Alpha 功能,旨在提高 KFServing 的可伸缩性。要了解有关多模型服务动机和实现细节的更多信息,请深入了解 KFServing GitHub 中的详细信息。请注意,此接口可能会发生变化。此实验性功能必须从推理服务 configmap 中启用。
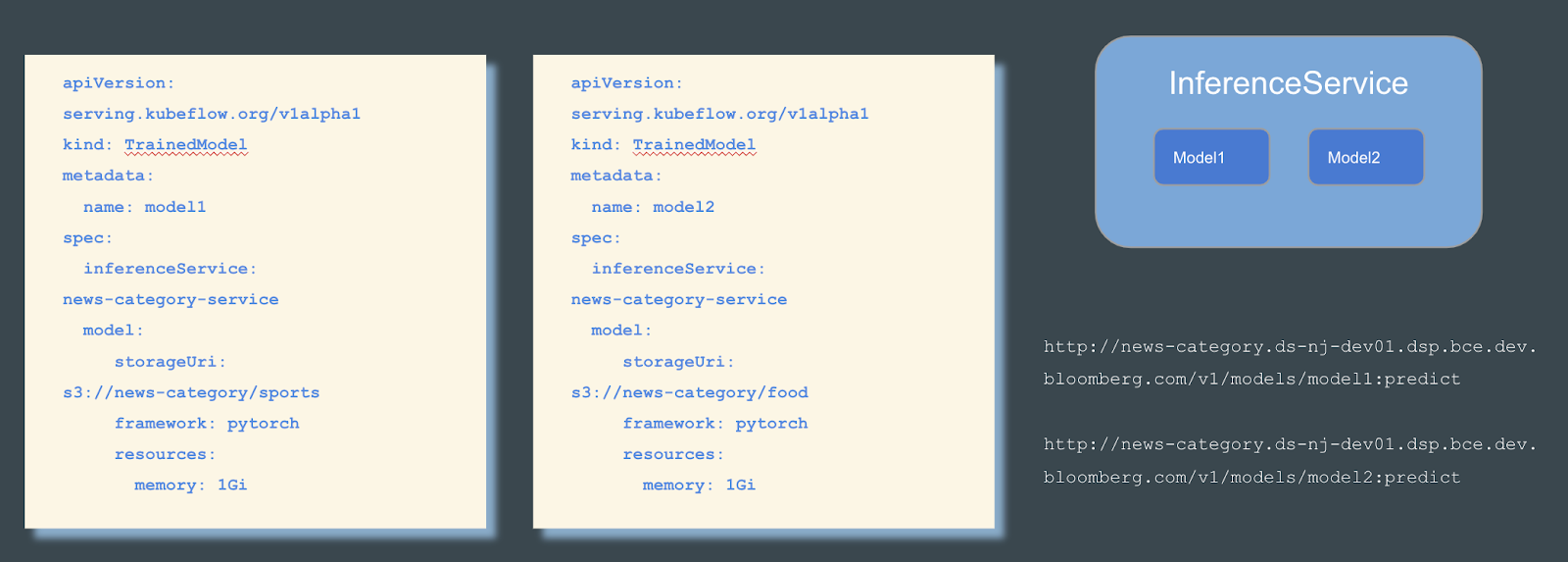
多模型服务适用于任何实现 KFServing V2 协议的模型服务器。更具体地说,如果模型服务器实现了 load 和 unload 端点,那么它就可以使用 KFServing 的 TrainedModel。目前支持的模型服务器包括 Triton、SKLearn 和 XGBoost。单击 Triton 或 SKLearn 查看如何运行多模型服务的示例。
在 OpenShift 上运行 KFServing
RedHat OpenShift 是企业级 Kubernetes 发行版的市场领导者,通过在 OpenShift 上启用 KFServing,我们确保运行经过实战验证的 OpenShift 平台的企业可以利用 KFServing 在 OpenShift 上实现无服务器模型推理,包括如何利用 OpenShift Service Mesh。请按照此处的详细说明在 OpenShift 上运行 KFServing

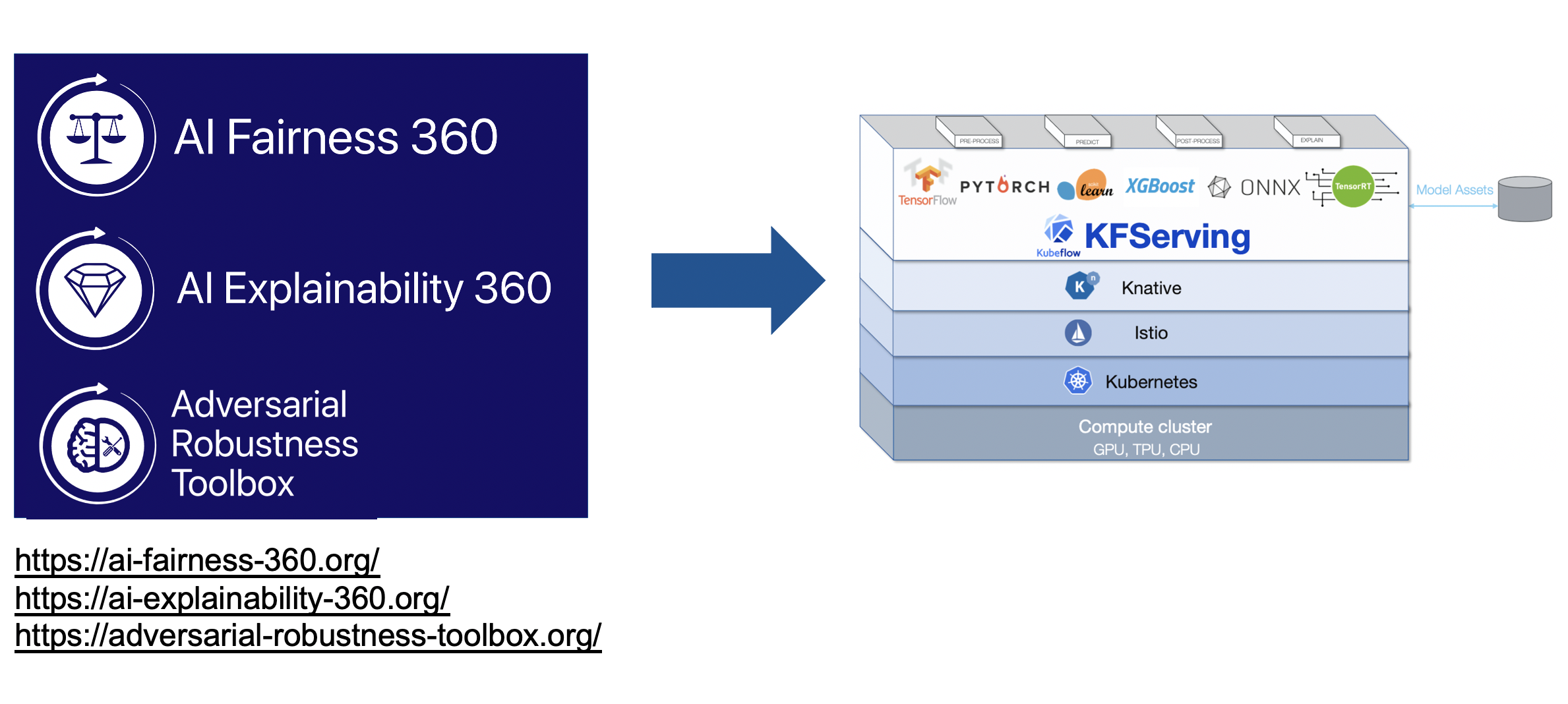
KFServing 中关于人工智能公平性、可解释性和对抗鲁棒性的 LFAI 可信 AI 项目
信任和责任应该是人工智能的核心原则。LF AI & Data 可信 AI 委员会 是一个全球性组织,致力于制定政策、指南、工具和项目,以确保可信赖的 AI 解决方案的开发,并且我们将 LF AI 的 AI Explainability 360、Adversarial Robustness 360 集成到 KFServing 中,以提供生产级别的可信 AI 能力。请在以下链接中查找有关这些集成的更多详细信息
AI Explainability 360-KFServing 集成
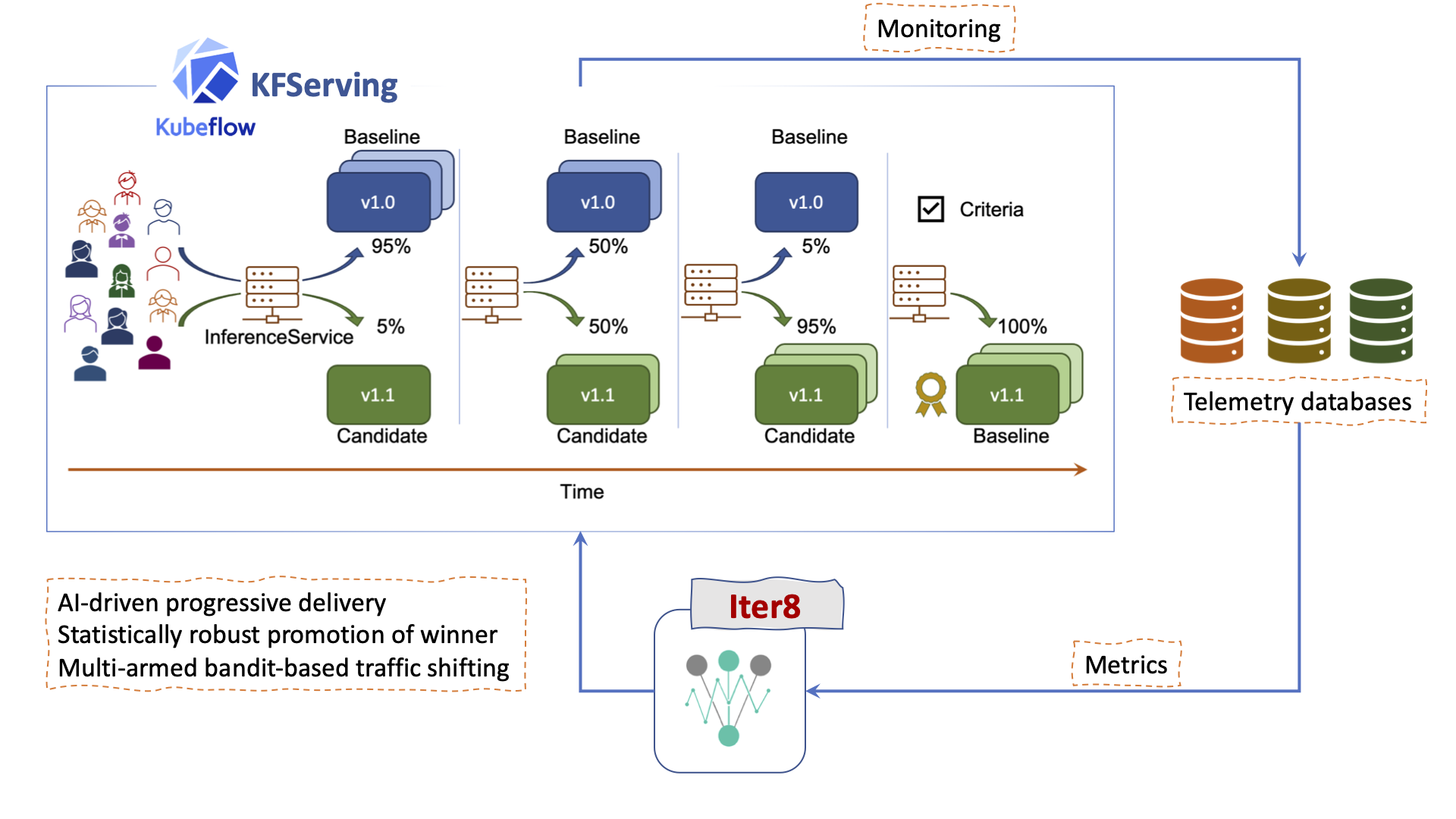
在 KFServing 中使用 Iter8 进行指标驱动的自动化发布
Iter8-KFServing 支持在 Kubernetes 和 OpenShift 集群上服务的 ML 模型进行指标驱动的实验、渐进式交付和自动化发布。Iter8 实验 可用于安全地将模型的不同版本暴露给流量,同时收集和评估指标,从而智能地将流量转移到模型的获胜版本。在 Iter8-KFServing 仓库中了解如何进行设置和运行。
加入我们,在 Kubernetes 上构建可信模型推理平台
请加入我们 KFServing GitHub 仓库,试用它,提供反馈,并提出问题。此外,您还可以通过以下方式与我们联系
-
要在 OpenShift 和 Kubernetes 上贡献并构建企业级的端到端机器学习平台,请 加入 Kubeflow 社区 并提出任何问题、评论和反馈!
-
如果您需要帮助在您的本地 Kubernetes 平台、OpenShift 或 IBM Cloud 上部署和管理 Kubeflow,请 与我们联系。
-
如果您对数据和人工智能领域的开源项目感兴趣,包括 Kubeflow、Kafka、Hive、Hue 和 Spark,以及如何以云原生的方式将它们整合在一起,请 查看 OpenDataHub。
贡献者致谢
我们要感谢所有 KFServing 贡献者的杰出工作!