Kubeflow 1.2 版本发布公告
Kubeflow 1.2 博客文章
来自 Kubeflow 创始人的特别致辞
三年前 (!!),我们(Jeremy Lewi、Vish Kannan 和 David Aronchick)在 Kubecon 的舞台上首次介绍了 Kubeflow。我们完全没有想到它会发展到今天这样——数千个 GitHub 星标、数万次提交,以及一个构建了最灵活、最具扩展性的机器学习平台的社区。最棒的是,它不是由一家庞大的公司支持,并且需要你“升级”才能使用;我们将它完全免费提供!向你们所有人所做的一切致敬,我们对未来的三年(以及之后的三年)充满期待。谢谢!
宣布发布 Kubeflow v1.2
Kubeflow 社区发布的 Kubeflow 1.2 软件版本包含大约 100 项用户请求的增强功能,旨在改进模型构建、训练、调优、ML 流水线和模型服务。本文包含一个发布亮点部分,详细介绍了由 Kubeflow 应用工作组 (WG)、SIG 和生态系统合作伙伴贡献的 1.2 版本重要特性。Kubeflow 1.2 更新日志提供了 1.2 版本交付内容的快速概览。
该版本由开发者进行了验证、测试和文档编写,目前正由用户、云提供商和商业支持合作伙伴在流行平台(如 AWS、Azure、GCP、IBM 等)上进行验证、测试和文档编写。社区正在努力采用一种更可持续的方法来拥有和维护测试基础设施。
对于 1.2 版本,AWS 构建并贡献了一个共享的测试基础设施,它为工作组负责人提供了足够的权限来识别问题,并测试提出的解决方案直到完成。目前,大多数工作组(AutoML、Training-Operators、KFServing、Deployments、Manifests)已将其测试迁移到此解决方案。因此,测试基础设施阻塞时间显著下降,这对用户和贡献者来说都是好事。
如何参与
社区持续壮大,我们邀请新用户和贡献者加入工作组和社区会议。以下为希望参与 Kubeflow 社区的人士提供了一些有用的链接:
- 加入 Kubeflow Slack 频道
- 加入 kubeflow-discuss 邮件列表
- 参加 每周社区会议
- 查阅发布亮点部分的工作组会议记录(记录中包含精彩的讨论和会议时间)
如果您有任何问题或遇到任何困难,请利用 Kubeflow Slack 频道和/或通过 GitHub 上的 Kubeflow 提交 bug。
后续计划
社区已开始讨论 Kubeflow 1.3。Arrikto 已同意牵头 1.3 版本的发布管理流程,社区将继续收集用户和贡献者的反馈,以定义、开发和交付新功能。再接再厉,不断进步!
特别感谢 Constantinos Venetsanopoulos (Arrikto)、Animesh Singh (IBM)、贾欣珊 (字节跳动)、肖瑶 (AWS)、David Aronchick (Azure)、Dan Sun (彭博社)、Andrey Velichkevich (思科)、Matthew Wicks (Eliiza)、Willem Pienaar (Feast)、袁巩 (谷歌)、James Wu (谷歌)、Jeremy Lewi (谷歌)、Josh Bottum (Arrikto)、Chris Pavlou (Arrikto)、Kimonas Sotirchos (Arrikto)、Rui Vasconcelos (Canonical)、Jeff Fogarty (美国银行)、Karl Shriek (AlexanderThamm) 和 Clive Cox (Seldon) 在 1.2 版本和此文章中的帮助。
发布亮点部分
工作组:AutoML / Katib
工作组会议记录:Katib 工作组会议记录
整体收益:更好的模型准确性,更好的基础设施利用率
整体描述:Katib 0.10 版本及全新的 v1beta1 API 已随 Kubeflow 1.2 版本发布。通过自动配置超参数来交付更准确且占用更少基础设施的模型,AutoML / Katib 利用提前停止技术简化了寻找模型最优参数集的过程。可以在 Katib Experiment 期间通过自定义 Kubernetes CRD 支持来编排复杂的流水线。
特性名称:提前停止
特性描述:通过使用 Katib 提前停止技术节省您的集群资源。允许使用 Median Stopping Rule 算法。
特性收益:您无需修改训练源代码即可使用该特性!提前停止可与所有 Katib 算法一起使用。
特性名称:在新 Trial 模板中支持自定义 CRD 和新 Trial 模板。
特性描述:您只需两个简单步骤即可将自定义 Kubernetes 资源集成到 Katib。灵活的方式在新的 Trial 模板设计中发送您的超参数,这是一个有效的 YAML。
特性收益:在 Katib Experiment 中定义 Tekton Pipeline。即使您的模型配置是 JSON scikit learn Pipeline,您也能够传递超参数。
特性名称:恢复 Experiments
特性描述:实现了恢复 Katib Experiments 的各种方法。将 Experiment 的 Suggestion 数据保存在自定义卷中。使用 Katib 配置修改您的卷设置。
特性收益:在您的 Experiment 完成后释放您的集群资源。
特性名称:多种提取指标的方式
特性描述:您可以为您的 Experiment 指定指标策略。Katib 根据这些值计算 Experiment 目标。您可以查看每个 Trial 的详细指标信息。
特性收益:当您的模型在最终训练步骤产生必要值时,获得正确的优化结果。
工作组:KFServing
工作组会议记录:KFServing 工作组会议记录
整体收益:KFServing 使 Kubernetes 上的无服务器推理成为可能,并为 TensorFlow、XGBoost、scikit-learn、PyTorch 和 ONNX 等常见机器学习 (ML) 框架提供高性能、高抽象度的接口,以解决生产模型服务用例。
整体描述:Kubeflow 1.2 包含了 KFServing v0.4.1,重点在于在 OpenShift 上启用 KFServing,并提供更多功能,例如将 batcher 模块添加为 sidecar,Triton 推理服务器更名和集成,将 Alibi explainer 升级到 0.4.0,将 logger 更新到 CloudEvents V1 协议,并允许在数据平面上自定义 URL 路径。此外,最低 Istio 版本现已更新至 v1.3.1,KNative 版本已移至 KNative 0.14.3。更多详细信息可参见此处和此处。
特性名称:将 batcher 模块添加为 sidecar #847 @zhangrongguo
特性描述:KFServer Batcher 接收用户请求,将它们批处理,然后发送到“InferenceService”。Batcher 特性描述
特性收益:更快的推理请求响应时间,提高基础设施利用率
特性名称:Alibi explainer 升级到 0.4.0 #803 @cliveseldon
特性描述:增强功能包括用于黑盒模型 SHAP 分数的 KernelSHAP explainer 以及 LinearityMeasure 算法的文档。此交付包含 explainer 和 explanation 对象的新 API,它们提供了各种改进,但包含破坏性变更。
特性收益:此交付提高了理解哪些特征影响模型准确性的能力,并改进了操作。
特性名称/描述:Triton 推理服务器更名和集成 #747 @deadeyegoodwin
工作组:Pipelines
工作组会议记录:http://bit.ly/kfp-meeting-notes
整体收益:当您有新数据和新代码时,简化模型创建过程
整体描述:Kubeflow Pipelines 是一个基于容器构建和部署可移植、可扩展的机器学习 (ML) 工作流的平台。Kubeflow Pipelines 平台包括:
- 用于管理和跟踪 experiments、jobs 和 runs 的用户界面 (UI)。
- 用于调度多步骤 ML 工作流的引擎。
- 用于定义和操作 pipelines 和 components 的 SDK。
- 用于使用 SDK 与系统交互的 Notebooks。
Kubeflow Pipelines 的目标如下:
- 端到端编排:启用并简化机器学习流水线的编排。
- 轻松实验:让您轻松尝试众多想法和技术,并管理您的各种 trial/experiments。
- 轻松重用:使您能够重用 components 和 pipelines,以便快速创建端到端解决方案,而无需每次都重新构建。
Kubeflow Pipelines 在几个补丁版本中正在稳定。同时,我们在标准化流水线 IR(中间表示)方面取得了很大进展,这将作为不同执行引擎的统一流水线定义。
特性名称:提供带有 Tekton 后端的 Kubeflow Pipelines
特性描述:经过大量努力,我们已使 Kubeflow Pipelines 在 Tekton 上端到端运行并在开源中可用。此外,它在 IBM Cloud 上的 Kubeflow 部署中默认提供,并可在 OpenShift 上部署。
特性收益:Tekton 支持
如果您是 Tekton 的现有用户,或 Tekton 的爱好者,或正在运行 OpenShift Pipelines,请将其运行在 Kubeflow Pipelines 之上。更多详情请参见:
https://developer.ibm.com/blogs/kubeflow-pipelines-with-tekton-and-watson/
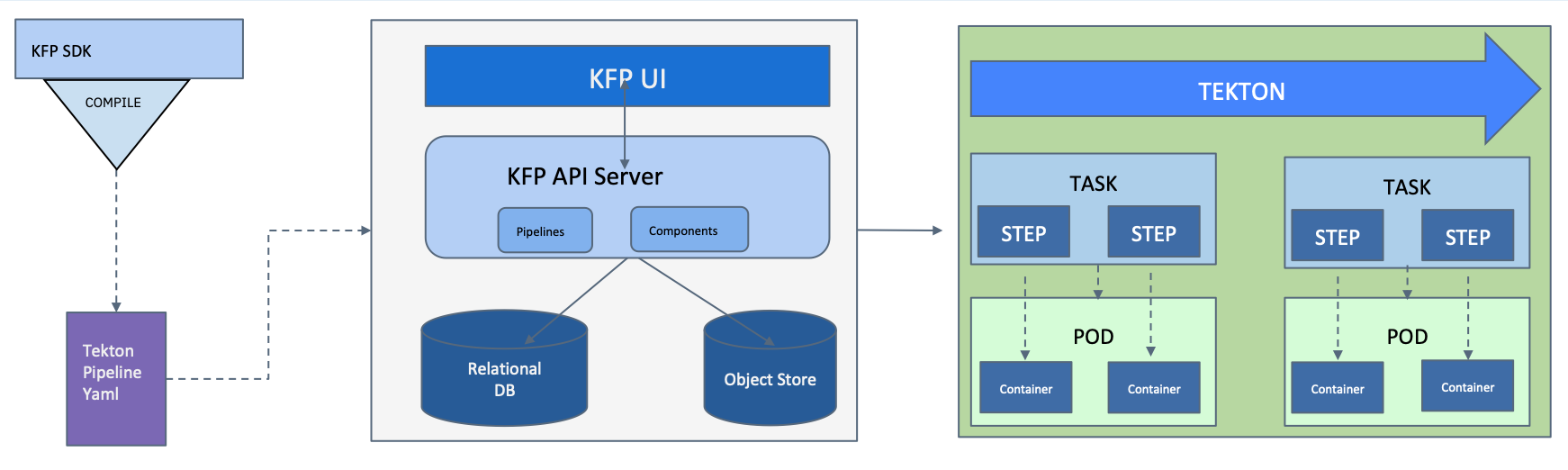
特性名称:稳定 Kubeflow Pipelines 1.0.x
特性描述:我们正在通过几个补丁版本来稳定 Kubeflow Pipelines:Kubeflow Pipelines 1.0.4 更新日志包含约 20 项修复和约 5 项 minor features。
工作组:Notebooks
工作组会议记录:即将发布
整体收益:用于模型开发的交互式、实验性编码环境
整体描述:Notebooks 提供了一个高级、交互式的编码环境,用户和团队可以共享并利用 kubernetes 命名空间进行隔离和资源利用
特性名称:Affinity/Toleration 配置,#5237
特性描述:增加了 Kubeflow 管理员设置 Affinity/Toleration 配置组的能力,用户可以从下拉列表中选择。
特性收益:允许对 Notebook pod 的调度进行更细粒度的选择。
特性名称:重构 Notebooks Web App
特性描述:重构的详细信息在这些交付中定义:
- 不同 python 后端之间的通用代码,#5164
- 使用通用前端代码创建 Angular Library,#5252
- 重构 JWA 后端以利用通用代码,#5316
- 在 crud-web-apps 中初始化 Jupyter web app 前端,#5332
特性收益:重构将使未来更容易与其他 web apps 集成 - Tensorboard、卷管理器。
特性名称:在保持状态的同时停止和重启 Notebooks,#4857 #5332
注意:更新后的 Notebooks web app 的 artifact 将在 1.2.1 或更高版本中可用
特性描述:在中央仪表板中实现一个“关闭服务器”按钮,将服务器的有状态集缩容到零,以及一个“启动服务器”按钮,将其重新扩容。
特性收益:保存工作,节省基础设施资源
工作组:Training-Operators
工作组会议记录:即将发布
整体收益:使用简化分布式计算的 operator 加快模型开发
特性名称:Training Operator 贡献者在 Kubeflow 1.2 中提供了以下修复和改进:
- 将 mxnet-operator manifest 更新到 v1 (#1326, @Jeffwan)
- 修正 XGBoostJob CRD 组名称并添加 singular name (#1313, @terrytangyuan)
- 修复 XGBoost Operator manifest 问题 (#1463, @Jeffwan)
- 将 Pytorch operator e2e 测试移至 AWS Prow (#305, @Jeffwan)
- 在 MXNet Operator 中支持 BytePS (#82, @jasonliu747)
- 修复 tf-operator 中 conditions 为空时的错误 (#1185, @Corea)
- 修复 MXNet Operator 中的 successPolicy 逻辑 (#85, @jasonliu747)
SIG:模型管理
整体收益:能够找到模型版本及其子组件,包括元数据
SIG 会议记录:模型管理 SIG 会议记录
整体描述:该 SIG 旨在定义和开发 Kubeflow 的模型管理解决方案,该方案将更容易组织和查找模型及其 artifact。此外,几位贡献者正在提交关于如何定义 ML 模型和数据的各种数据类型的提案,目标是推动更广泛的元数据标准,以及模型在 ML 平台、云和框架之间的互操作性。这些提案正在努力定义模型和数据类型的本体以及搜索和组织该元数据的工具。
来自 Kubeflow Pipelines 贡献者、模型管理 SIG、Seldon 以及 David Aronchick (Azure) 的 MLSpec 的提案正在讨论中。请在下方找到这些提案的链接:
- Kubeflow Pipelines 中的 ML 数据
- 来自 David Aronchick 的 ML Spec
- 来自 SIG 技术负责人 Karl Schriek 的模型管理提案
- Seldon 关于初始元数据类型的提案
生态系统:Seldon
整体收益:部署、扩展、更新使用 Kubeflow 构建的模型。
整体描述:Seldon 处理生产机器学习模型的扩展,并提供开箱即用的高级机器学习功能,包括高级指标、请求日志记录、解释器、异常检测器、A/B 测试和金丝雀发布。
Kubeflow 1.2 随附 Seldon 的 1.4 版本。Seldon 的此版本增加了模型部署和推理的更多功能,包括向已部署模型添加批处理和流式接口。它还允许通过添加 KEDA 和 Pod Disruption Budget 选项来对已部署模型如何与 Kubernetes 交互进行细粒度控制。最后,它开始与 KFServing 兼容的过程,允许使用 Seldon、KFServing 和 NVIDIA Triton 支持的 V2 Dataplane。
版本:1.4.0
特性名称:Stream 和 Batch 支持
特性描述:支持原生 Kafka 集成的流式传输。支持从云存储到云存储的批量预测。
特性收益:允许 Seldon 用户根据需要通过 RPC、Stream 或 Batch 与其模型交互。
特性名称:通过 KEDA 和 PDBs 扩展 Kubernetes 控制
特性描述:允许通过 KEDA 指标进行自动扩缩容和添加 pod disruption budgets,从而对已部署模型进行细粒度控制。
特性收益:在生产集群中大规模管理模型。
特性名称:Alpha V2 Dataplane
特性描述:使用更新的 python 服务器以及对 V2 Dataplane(NVIDIA Triton、KFServing、Seldon)的支持来运行自定义 python 模型
特性收益:利用跨项目支持的标准强大协议。
生态系统:Kale
整体收益:Kubeflow 工作流工具,直接从 Notebook 或 IDE(例如 VSCode)简化 ML 流水线构建和版本控制
Kale GitHub 仓库:https://github.com/kubeflow-kale/kale
Kale 教程:https://www.arrikto.com/tutorials/
整体描述:Kale 允许您将运行在笔记本电脑或云上的 Jupyter Notebook 部署到 Kubeflow Pipelines,而无需任何 Kubeflow SDK 的样板代码。您只需通过注解 Notebook 的代码单元格并点击 Jupyter UI 中的部署按钮即可定义流水线。Kale 将负责将 Notebook 转换为有效的 Kubeflow Pipelines 部署,处理数据依赖性解析和流水线生命周期管理。
特性名称:Dog Breed Classification 示例
特性描述:用于构建图像分类模型的简化流水线教程
特性收益:更快地理解 ML 工作流,通过超参数调优交付模型
特性名称:Kale 与 Katib 集成
特性描述:通过流水线实现自动超参数调优和可重现的 Katib trial
特性收益:更好的模型准确性和易于重现和调试
特性名称:使用 Kale 与 Rok 集成的 Katib Trial 的流水线步骤缓存
特性描述:Kale 识别流水线步骤是否已运行过,并从 Rok 获取完整结果并插入到流水线处理中
特性收益:更快的超参数调优,减少基础设施利用率
生态系统:Feast
整体收益:Feast 允许团队在生产环境中注册、注入、服务和监控机器学习特征。
工作组会议记录:https://tinyurl.com/kf-feast-sig
整体描述:Feast 的最新版本是 Feast 社区共同努力的结果,旨在使 Feast 在 Google Cloud 以外的更多环境中可用。我们移除了所有对托管服务的硬性耦合,并使其能够在 AWS 和本地运行。
版本:Feast 0.8
特性名称:支持 AWS
特性描述:Feast 0.8 现在支持在 AWS 上部署,原生支持 EMR 上的作业管理,并支持 S3 和 Kinesis 作为数据源。
特性收益:最终使得在 AWS 上的 Kubeflow 用户可以运行 Feast
特性名称:仅批量注入
特性描述:允许团队将数据注入到 stores 中,而无需通过流传输数据。
特性收益:与 stream-first 方法相比,提供了更优的注入性能。
特性名称:仅本地模式
特性描述:使得可以在没有任何外部基础设施的情况下运行 Feast,仅使用 Docker Compose 或 Minikube
特性收益:降低了新用户的入门门槛,并使 Feast 的测试和开发更加容易
生态系统:On-Prem SIG
描述:on-prem SIG 在本次发布期间正式创建,旨在开发 Kubeflow 在本地安装中的最佳实践。在新版本中,该 SIG 还确保了测试基础设施,以便提供经过充分测试的参考架构。
SIG 会议记录:https://bit.ly/2LyTh14
Slack 频道:https://kubeflow.slack.com/archives/C01C9NPD15H
平台:AWS
描述:通过为 Kubeflow AWS 部署启用 E2E 测试,提高了可靠性,增加了测试覆盖率,改善了 Kubeflow notebook 用户体验。
平台:IBM
描述:对于本次版本在 IBM Cloud 上的 Kubeflow,流水线和安全性是重点。在流水线方面,带有 Tekton 的 Kubeflow Pipelines 可在 IBM Cloud Kubernetes Service 上部署,并默认包含在 IBM Cloud 上的 Kubeflow 部署中。在安全性方面,我们已启用与 IBM Cloud AppId 的集成作为认证提供商,而不是 Dex。使用 AppID 时,它将身份提供商委托给 IBM Cloud,后者拥有内置的身份提供商(Cloud Directory、SAML、使用 Google 或 Facebook 等的社交登录)或自定义提供商。此外,为了使用 HTTPS 保护 Kubeflow 认证,我们提供了使用 IBM Cloud Network Load Balancer 的集成说明。
平台:GCP
描述:改进了安装和升级的用户体验和可靠性。将管理集群中的 Cloud Config Connector 升级到最新版本。
平台:Azure
描述:我们添加了关于使用 Azure Active Directory 支持多租户来部署 Kubeflow 的说明。此外,我们还记录了将元数据存储替换为托管 Azure MySQL 数据库实例的步骤。
平台:OpenShift
描述:我们本次发布的重点是创建可以在 OpenShift 4.x 上安装 Kubeflow 组件的 OpenShift 栈。我们将栈架构设计为用户可以通过在 kfdef 中添加或删除 kustomizeConfig 条目来选择要安装的组件。当前支持的组件有 istio、单用户流水线、带有自定义 Tensorflow notebook 镜像的 Jupyter notebooks、带有自定义镜像的 profile controller、Katib、pytorch 和 Tensorflow job operators 以及 Seldon。您可以从 OpenShift Catalog 中的 Open Data Hub 社区 operator 使用 OpenShift kfdef 在 Openshift 上安装 Kubeflow 1.2。
平台:MicroK8s
描述:Kubeflow 是 MicroK8s 的内置附加组件,现在默认包含 Istio v1.5。
平台:MiniKF
描述:MiniKF 目前正在与 Kubeflow 1.2 进行测试,并将在验证测试和文档完成后提供更新的 MiniKF 版本。请在此处找到有关 MiniKF 的更多信息:https://www.arrikto.com/get-started/。您还可以在此处找到指导您完成端到端数据科学示例的教程:https://www.arrikto.com/tutorials