Kubeflow MPI Operator 介绍与行业应用
Kubeflow 最近发布了它的第一个主要版本 1.0,使得机器学习工程师和数据科学家能够轻松利用云资产(公有云或私有云)进行机器学习工作负载。在这篇文章中,我们想介绍 MPI Operator (文档),它是 Kubeflow 的核心组件之一,目前处于 alpha 阶段,它使得在 Kubernetes 上运行同步的、allreduce 风格的分布式训练变得容易。
目前主要有两种分布式训练策略:一种基于参数服务器,另一种基于集体通信原语,例如 allreduce。
基于参数服务器的分布式策略依赖于中心化的参数服务器来协调工作节点,负责从工作节点收集梯度并将更新后的参数发送给工作节点。下图展示了在这种分布式训练策略下参数服务器和工作节点之间的交互。
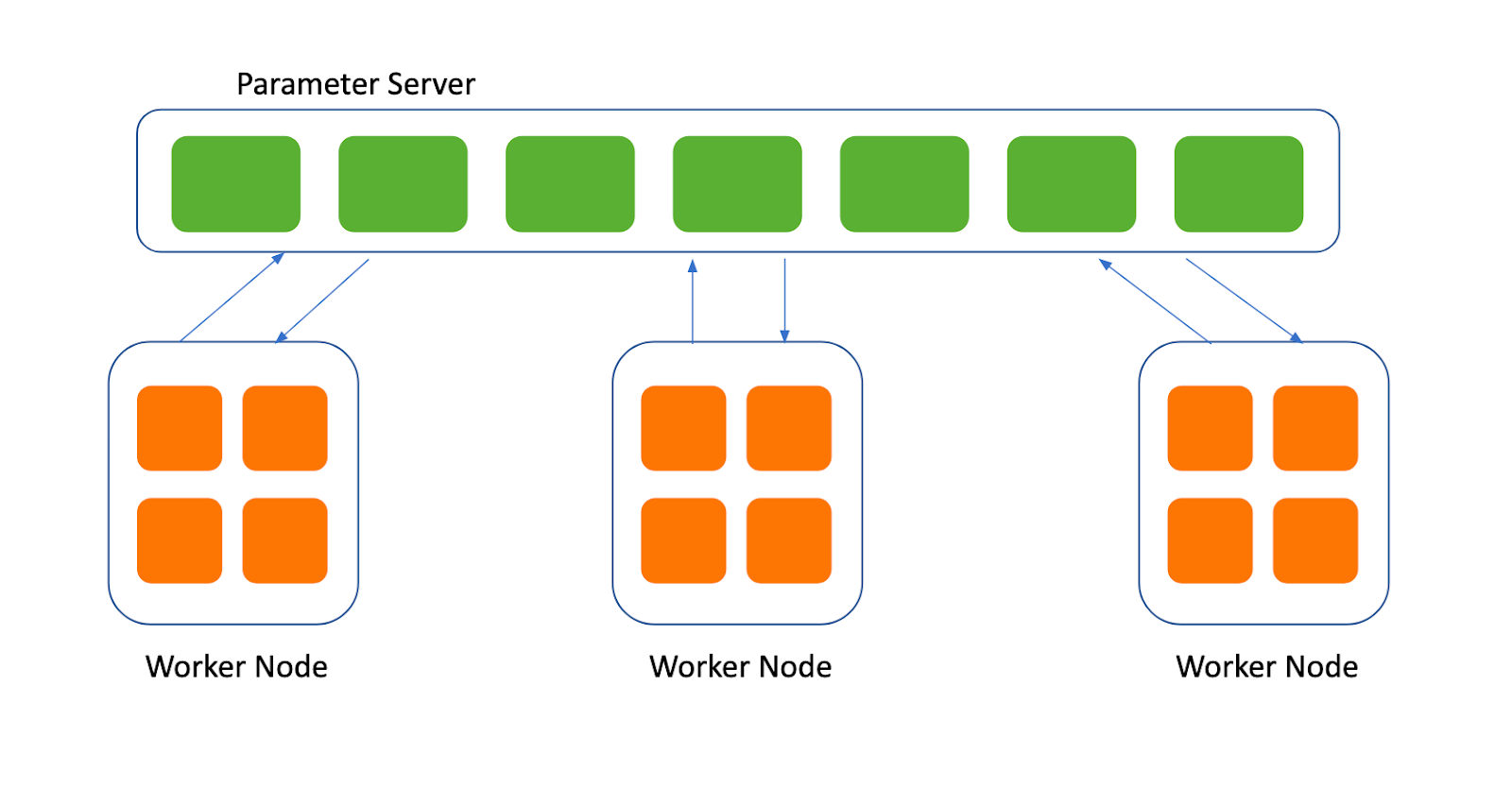
虽然基于参数服务器的分布式训练可以通过增加更多工作节点和参数服务器来支持训练非常大的模型和数据集,但为了优化性能,还需要应对额外的挑战
-
确定工作节点数量与参数服务器数量的合适比例并不容易。例如,如果只使用少量参数服务器,网络通信很可能成为训练的瓶颈。
-
如果使用大量参数服务器,通信可能会使网络互连饱和。
-
工作节点和参数服务器的内存配额需要精细调整,以避免内存不足错误或内存浪费。
-
如果模型可以适应每个工作节点的计算资源,将模型划分到多个参数服务器会引入额外的维护和通信开销。
-
为了支持容错,我们需要在每个参数服务器上复制模型,这需要额外的计算和存储资源。
相比之下,基于集体通信原语(如 allreduce)的分布式训练在某些用例中可能更高效且更易于使用。在基于 allreduce 的分布式训练策略下,每个工作节点都存储一套完整的模型参数。换句话说,不需要参数服务器。基于 allreduce 的分布式训练可以解决上面提到的许多挑战
-
每个工作节点都存储一套完整的模型参数,无需参数服务器,因此在需要时很容易添加更多工作节点。
-
工作节点之间的故障可以通过重新启动失败的工作节点并从任何现有工作节点加载当前模型来轻松恢复。无需复制模型即可支持容错。
-
通过充分利用网络结构和集体通信算法,可以更有效地更新模型。例如,在 ring-allreduce 算法中,N 个工作节点中的每一个只需要与其两个对等工作节点通信 2 * (N − 1) 次即可完全更新所有模型参数。
-
扩展和缩减工作节点数量就像重建底层的 allreduce 通信器并重新分配工作节点之间的等级一样容易。
有许多现有的技术可用于提供这些集体通信原语的实现,例如 NCCL、Gloo 以及各种不同的 MPI 实现。
MPI Operator 提供了一个通用的 Custom Resource Definition (CRD),用于定义在单个 CPU/GPU、多个 CPU/GPU 和多个节点上的训练作业。它还实现了一个自定义控制器来管理 CRD,创建依赖资源,并协调期望状态。

与 Kubeflow 中仅支持一种机器学习框架的其他 Operator(如 TF Operator 和 PyTorch Operator)不同,MPI Operator 与底层框架解耦,因此可以很好地与许多框架(如 Horovod、TensorFlow、PyTorch、Apache MXNet)以及各种集体通信实现(如 OpenMPI)配合使用。
有关不同分布式训练策略、各种 Kubeflow Operator 之间比较的更多详细信息,请查看我们在 KubeCon Europe 2019 上的演讲。
API Spec 示例
我们一直与社区和行业采用者密切合作,改进 MPI Operator 的 API Spec,使其适用于许多不同的用例。以下是一个示例
apiVersion: kubeflow.org/v1alpha2
kind: MPIJob
metadata:
name: tensorflow-benchmarks
spec:
slotsPerWorker: 1
cleanPodPolicy: Running
mpiReplicaSpecs:
Launcher:
replicas: 1
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
command:
- mpirun
- python
- scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py
- --model=resnet101
- --batch_size=64
- --variable_update=horovod
Worker:
replicas: 2
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
resources:
limits:
nvidia.com/gpu: 1
请注意,MPI Operator 提供了一个灵活且用户友好的 API,与其他 Kubeflow Operator 保持一致。
用户可以通过修改模板中的相关部分,轻松定制其 launcher 和 worker pod 的 Spec。例如,定制使用各种类型的计算资源,如 CPU、GPU、内存等。
此外,以下是一个示例 Spec,它使用存储在 Kubernetes Volume 中的 TFRecords 格式的 ImageNet 数据执行分布式 TensorFlow 训练作业
apiVersion: kubeflow.org/v1alpha2
kind: MPIJob
metadata:
name: tensorflow-benchmarks
spec:
slotsPerWorker: 1
cleanPodPolicy: Running
mpiReplicaSpecs:
Launcher:
replicas: 1
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
command:
- mpirun
- python
- scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py
- --model=resnet101
- --batch_size=64
- --variable_update=horovod
Worker:
replicas: 2
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
resources:
limits:
nvidia.com/gpu: 1
架构
MPI Operator 包含一个自定义控制器,用于监听 MPIJob 资源的变化。创建新的 MPIJob 时,控制器会执行以下逻辑步骤
- 创建一个包含以下内容的 ConfigMap
-
一个辅助 shell 脚本,可供 mpirun 代替 ssh 使用。它调用 kubectl exec 进行远程执行。
-
一个 hostfile,列出 worker StatefulSet 中的 Pod(形式为 ${job-id}-worker-0, ${job-id}-worker-1, …),以及每个 Pod 中可用的槽位 (CPU/GPU)。
-
创建 RBAC 资源(Role、ServiceAccount、RoleBinding),以允许远程执行 (pods/exec)。
-
等待 worker Pod 准备就绪。
-
创建 launcher 作业。它在步骤 2 中创建的 ServiceAccount 下运行,并设置执行远程 mpirun 命令所需的必要环境变量。kubectl 二进制文件通过 init 容器交付到 emptyDir volume。
-
launcher 作业完成后,将 worker StatefulSet 中的副本数设置为 0。
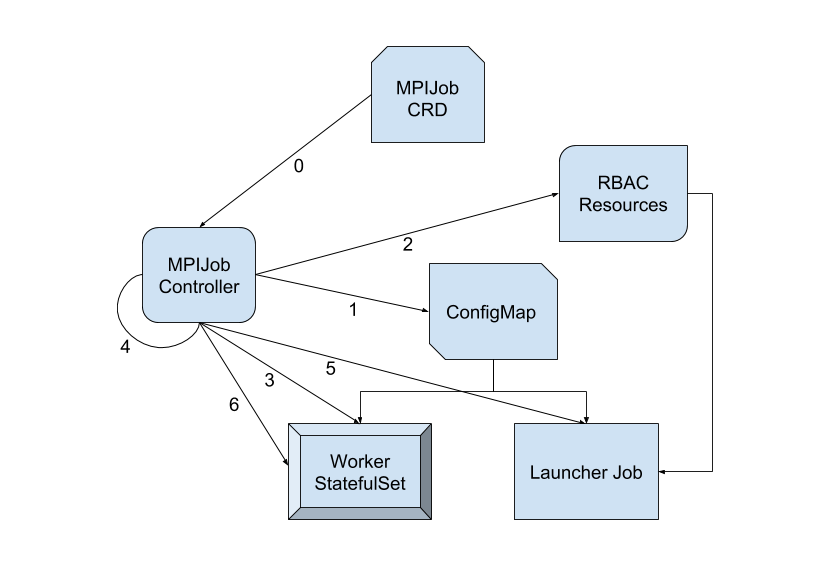
更多详细信息,请查阅 MPI Operator 的设计文档。
行业应用
在撰写本文时,已有 13 家已公开的行业采用者,还有许多其他公司一直与社区密切合作,共同达到了我们今天的成就。我们想展示 MPI Operator 在几家公司中的一些用例。如果贵公司希望被列入采用者名单,请在 GitHub 上给我们发送一个 pull request!
蚂蚁集团
在蚂蚁集团,我们管理着拥有数万个节点的 Kubernetes 集群,并已部署了 MPI Operator 以及其他 Kubeflow Operator。MPI Operator 利用网络结构和集体通信算法,让用户无需担心工作节点数量和参数服务器数量之间的合适比例,即可获得最佳性能。用户可以专注于构建模型架构,而无需花费时间调优下游的分布式训练基础设施。
由此产生的模型已广泛部署到生产环境中,并在许多不同的实际场景中经受住了实战考验。一个值得注意的用例是扫福——一款移动应用,用户可以通过增强现实扫描任意“福”(代表财富的汉字)参与抽奖,每位用户都会收到一个虚拟红包,其中包含一定金额的钱。
彭博社
彭博社是全球商业和金融信息与新闻领域的领导者,拥有海量数据——从历史新闻到实时市场数据以及介于两者之间的一切。彭博社的数据科学平台旨在让公司内部的机器学习工程师和数据科学家能够更轻松地在日常工作中利用数据和算法模型,包括在他们构建的最先进解决方案中使用的训练作业和自动化机器学习模型。
“彭博社的数据科学平台提供了一个类似于 Kubeflow 自己的 TFJob 的 TensorFlowJob CRD,使公司的数据科学家能够轻松训练神经网络模型。最近,数据科学平台团队通过 MPI Operator 在其 TensorFlowJob 中启用了基于 Horovod 的分布式训练,作为实现细节。彭博社数据科学平台团队使用 MPIJob 作为后端,使其能够快速为其机器学习工程师提供一种可靠的方式,在数小时内使用公司庞大的文本数据集训练 BERT 模型”,彭博社软件工程师郑成建(Chengjian Zheng)说。
白山云科技
白山云 Clever 是一个基于白山云容器云平台的人工智能云平台,具有强大的硬件资源管理和高效的模型开发能力。白山云的产品已部署在许多中国财富 500 强企业。
“在 Kubeflow 的 tf-operator、pytorch-operator 等帮助下,白山云 Clever 支持多种框架的 AI 模型训练,包括 TensorFlow、Apache MXNet、Caffe、PyTorch”,白山云 Clever 团队的 AI 基础设施工程师高策(Ce Gao)说。“同时,为了提高客户成熟度,客户也提出了对 RingAllReduce 分布式训练支持的需求。”
Kubeflow MPI Operator 是一个用于 allreduce 风格分布式训练的 Kubernetes Operator。白山云 Clever 团队采用了 MPI Operator 的 v1alpha2 API。Kubernetes 原生 API 使其易于与平台中现有系统配合使用。
Iguazio
Iguazio 提供了一个云原生数据科学平台,强调自动化、性能、可扩展性以及开源工具的使用。
据 Iguazio 创始人兼 CTO Yaron Haviv 说:“我们评估了各种机制,这些机制可以让我们以最少的开发工作量扩展深度学习框架,并发现将 Horovod 与 Kubernetes 上的 MPI Operator 结合使用是完成这项工作的最佳工具,因为它支持水平扩展,支持 TensorFlow 和 PyTorch 等多种框架,并且不需要太多额外编码或复杂地使用参数服务器。”
Iguazio 已将 MPI Operator 集成到其托管服务产品及其快速数据层中,以实现最大程度的可扩展性,并努力通过 MLRun(用于 ML 自动化和跟踪)等开源项目简化使用。请查阅这篇博客文章,其中包含一个示例应用程序,展示了 Iguazio 对 MPI Operator 的使用。
Polyaxon
Polyaxon 是一个用于在 Kubernetes 上进行可复现和可扩展机器学习的平台,它允许用户在其研究和模型创建过程中更快地进行迭代。Polyaxon 为数据科学家和机器学习工程师提供了一个简单的抽象层,以简化其实验工作流程,并提供了非常连贯的抽象层,用于使用流行的框架(如 Scikit-learn、TensorFlow、PyTorch、Apache MXNet、Caffe 等)训练和跟踪模型。
“一些 Polyaxon 用户和客户一直在寻求一种轻松进行 allreduce 风格分布式训练的方法,MPI Operator 是提供这种抽象的完美解决方案。Polyaxon 已部署在多家公司和研究机构,公共 docker hub 的下载量已超过 900 万”,Polyxagon 的联合创始人 Mourad Mourafiq 说。
社区与贡献号召
我们衷心感谢来自 11 家组织(包括阿里巴巴云、亚马逊云科技、蚂蚁集团、彭博社、白山云科技、谷歌云、华为、Iguazio、NVIDIA、Polyaxon 和腾讯)的 28 多位个人贡献者,他们直接为 MPI Operator 的代码库做出了贡献,还有许多其他人提交了 issues 或帮助解决了它们,提出了问题并给予了回答,并参与了鼓舞人心的讨论。我们制定了一份 路线图,它提供了 MPI Operator 在未来版本中发展方向的概览,我们欢迎社区的任何贡献!
没有一个极其活跃的社区,我们不可能取得这些里程碑。请访问我们的 社区页面,了解如何加入 Kubeflow 社区!
原文发布于 https://terrytangyuan.github.io,时间为 2020 年 3 月 17 日。