Kubeflow 和 Kale 通过自动超参数调优简化构建更优的 ML 流水线
大规模运行流水线从未如此简单。
大规模运行流水线从未如此简单。
TL;DR: 将 Notebook 转换为 Kubeflow 流水线,将其作为超参数调优实验运行,使用 MLMD 跟踪执行和工件,缓存并维护不可变的执行历史记录:Kale 将这一切集成到一个易于使用的统一工作流工具中。
大规模运行流水线从未如此简单
Kubeflow 的 Kale 正在成熟,并迅速成为将 Kubeflow 主要组件粘合在一起以提供连贯流畅的数据科学体验的“超级食品”。凭借其最新版本,Kale 提供了一个端到端的工作流程,涵盖了 Jupyter Notebooks、Kubeflow 流水线、使用 Katib 进行超参数调优、使用 ML Metadata (MLMD) 跟踪元数据以及通过缓存实现更快的流水线执行。
如果您是 Kale 的新手,请参阅这篇简短介绍以开始使用!
在这篇博文中,您将了解 Kale 在 0.5 版本中为机器学习社区带来的新特性,并学习如何通过精选示例上手。
新形象
首先,我们很高兴公布 Kale 的新标志。感谢 Konstantinos Palaiologos (Arrikto) 设计了这个全新的现代 Kale 叶子标志。从现在起,这将是项目的全新形象。

超参数调优
v0.5 版本的主要新特性是支持使用 Katib 运行流水线。Katib 是 Kubeflow 用于运行通用超参数调优作业的组件。就像您只需按一个按钮即可将 notebook 转换为流水线一样,现在您也可以按一个按钮,让 Kale 在该流水线上启动一个超参数作业。您只需告诉 Kale HP 调优作业应该搜索什么。
运行超参数调优作业可以极大地提升您项目取得良好结果的效率。*手动*运行模型无数次,使用不同的参数组合,然后汇总和比较它们,这个过程既容易出错又效率低下。将这项工作委托给自动化流程可以让您更快、更高效、更准确。
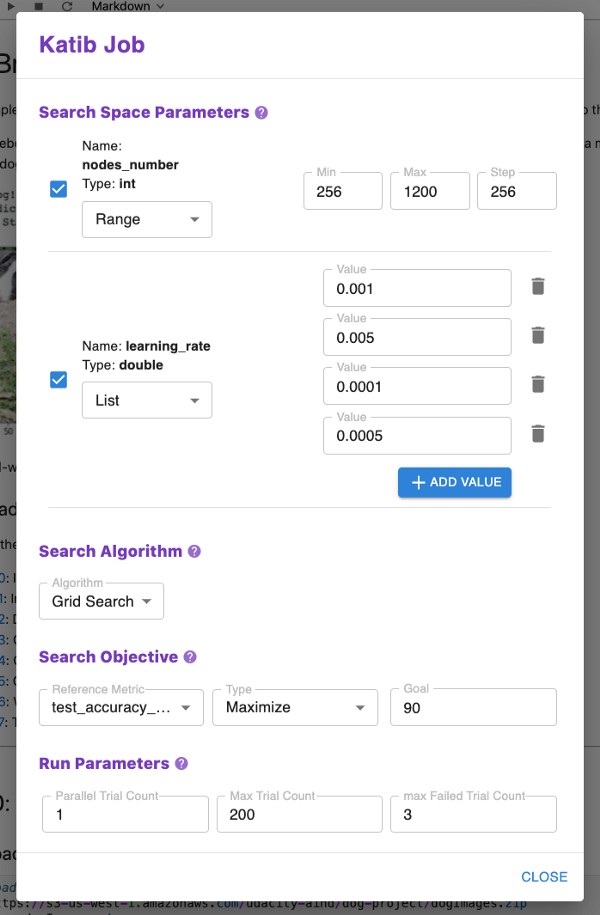
Katib 对它实际运行的作业(在 Katib 行话中称为试验 Trials)一无所知。Katib 支持将试验作为简单的 Jobs(即 Pods)、BatchJobs、TFJobs 和 PyTorchJobs 运行。Kale 0.5 将 Katib 与 Kubeflow 流水线集成。这使得 Katib 试验可以在 KFP 中作为流水线运行。流水线运行的指标被提供,以帮助进行模型性能分析和调试。Kale 只需用户提供搜索空间、优化算法和搜索目标。
Kale 还将确保一个 Katib 实验的所有运行最终统一并分组在一个单独的 KFP 实验下,以便轻松搜索和隔离特定的作业。
Kale 还将直接在 notebook 中显示正在运行的实验的实时视图,以便您了解还有多少流水线正在运行,并在完成后知道哪个表现最佳。
新特性
流水线参数和指标
为了使用超参数调优运行流水线,流水线需要能够接受参数并产生指标。现在,使流水线能够做到这一点变得异常简单。Kale 提供了两个新的单元格标签:pipeline-parameters 和 pipeline-metrics。
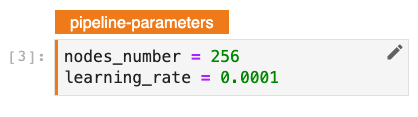
在包含某些变量的任何单元格上指定 pipeline-parameters 标签将指示 Kale 将它们转换为流水线参数。然后这些值将被传递给实际使用它们的流水线步骤。
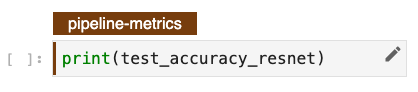
如果您希望流水线产生一些指标,只需在 notebook 末尾打印它们,并将 pipeline-metrics 标签分配给该单元格。Kale 将负责理解哪些步骤产生指标,您将在 KFP 控制面板中看到它们出现。
丰富的 Notebook 输出
让您的流水线产生可由 Kubeflow 流水线控制面板捕获和显示的丰富输出(如图表、表格、指标等)一直以来都有些繁琐。您需要编写一些 KFP 特定的代码来生成 JSON 工件,然后由 KFP 解释。
如果您可以直接在 Notebook 中使用您喜欢的绘图库编写纯 Python 代码,并且当 Notebook 被编译成流水线时,这些图表能自动神奇地作为 KFP 输出出现,那会怎么样呢?
现在,当在流水线步骤中运行您的 notebook 代码时,Kale 会对其进行封装并将其送入 ipython 内核,以便 notebook 中产生的所有精美的工件也能在流水线中产生。Kale 会自动捕获所有这些丰富的输出,并指示 KFP 在控制面板中显示它们。实际上,notebook 中发生的一切现在也会在流水线中发生。执行上下文是完全相同的。
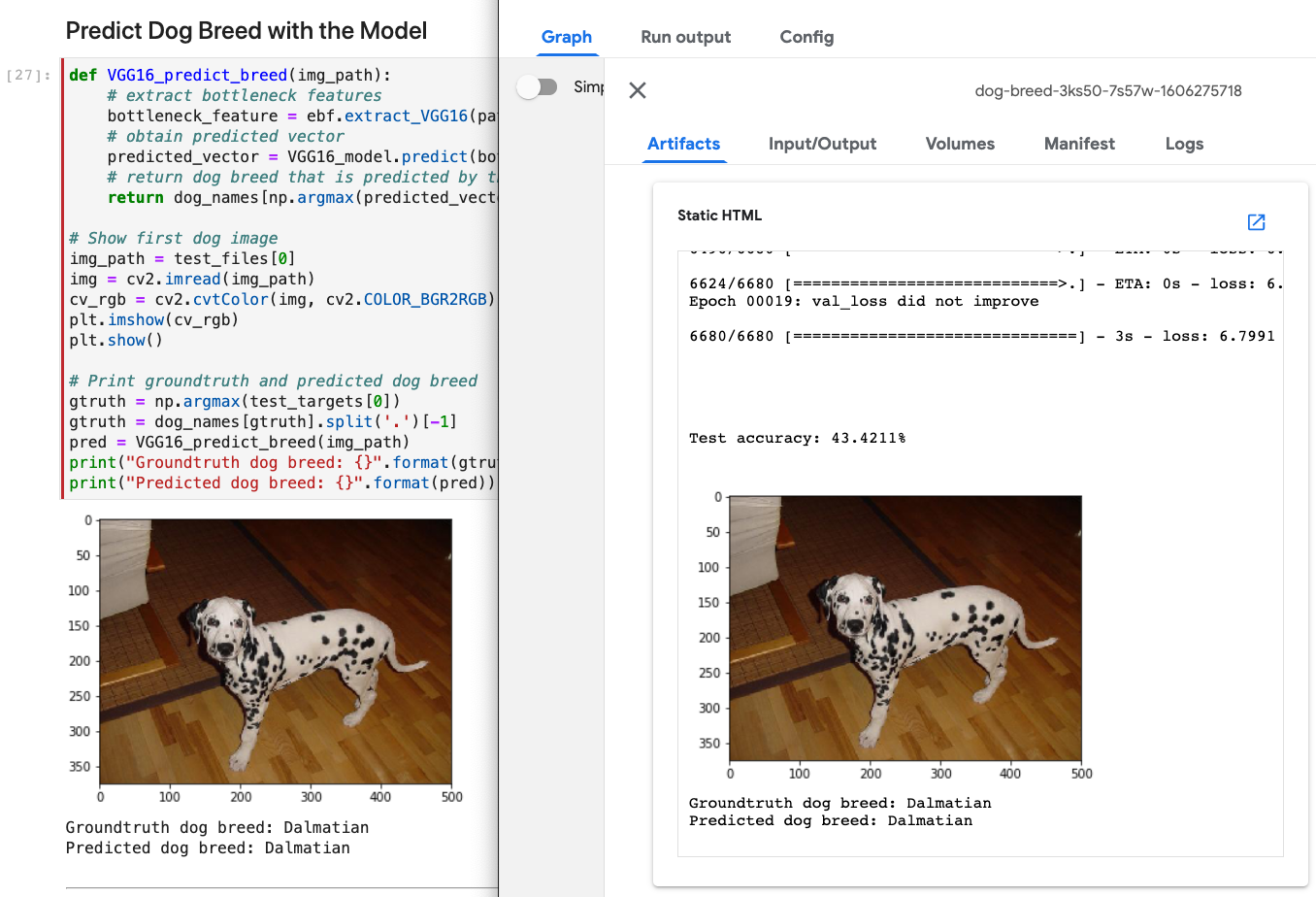 Notebook 中可见的任何丰富输出都会被 Kale 捕获并在 KFP 控制面板中显示。
Notebook 中可见的任何丰富输出都会被 Kale 捕获并在 KFP 控制面板中显示。
MLMD 集成
在协作式大规模运行可重现机器学习时,一个重要部分是能够跟踪流水线执行、它们的输入、输出以及它们之间的连接方式。Kubeflow 提供了一个 ML Metadata 服务,正是为此目的而生。该服务还包括一个血缘视图,使用户能够深入了解整个事件历史记录。
Kale 现已与此服务完全集成,自动记录每个新的执行以及流水线产生的所有工件。
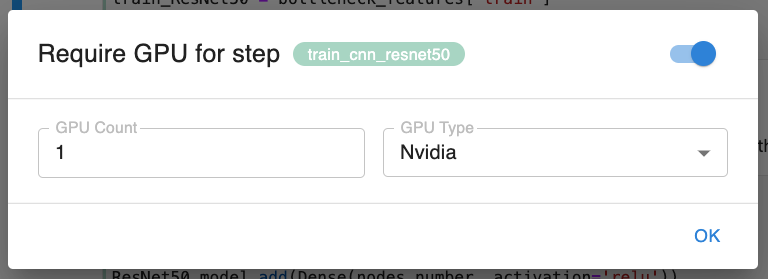
在 GPU 上运行
如果您需要在 GPU 节点上运行特定步骤,Kale 也能满足您的需求。现在,您可以通过专用的对话框直接从 notebook 注解步骤,每个步骤都可以有自己的注解。这只是第一个迭代,Kale 在不久的将来将支持向流水线步骤添加任何类型的 K8s 限制或注解。
整体 UI 和性能改进
新版本的 Kale JupyterLab 带来了大量的性能改进和 UI 增强。更新 notebook 单元格的注解现在将更轻松快捷。我们涵盖了许多边缘情况并解决了大量错误。单元格注解编辑器的 UI 与整体 Jupyter 风格更一致,并且更加直观易用。在此特别感谢 Tasos Alexiou (Arrikto) 花费无数时间理解 Jupyter 内部机制并改进我们的应用程序生命周期。
动手实践
要开始试用 Kale v0.5,请前往 GitHub 仓库并按照安装说明进行操作。如果您已经在运行 Kubeflow(无论是在您自己的集群中还是在 MiniKF 上),请使用镜像 gcr.io/arrikto/jupyter-kale:v0.5.0 启动一个新的 Notebook 服务器。
注意:Kale v0.5 需要在 Kubeflow ≥ 1.0 版本上运行。另外,请确保以下 Kubeflow 组件已更新如下:
-
Katib 控制器:gcr.io/arrikto/katib-controller:40b5b51a
-
Katib Chocolate 服务:gcr.io/arrikto/suggestion-chocolate:40b5b51a
我们将*很快*发布一个新版本的 MiniKF,其中包含许多改进,将使 Kale 的体验更好。您还将能够通过新的 Codelab 亲自尝试 Kale-Katib 集成。请继续关注 Arrikto 频道的更新。
未来展望
我们一直在寻求改进 Kale,并帮助数据科学家拥有从编写代码到训练、优化和服务模型的无缝 ML 工作流程。
我们很高兴能让 ML 社区试用这个新版本的 Kale 和即将到来的 MiniKF 更新。
特别要感谢 Arrikto 团队的各位成员 (Ilias Katsakioris, Chris Pavlou, Kostis Lolos, Tasos Alexiou),他们为交付所有这些新特性做出了贡献。