数据科学遇见DevOps:使用Jupyter、Git和Kubernetes进行MLOps
使用Jupyter、Papermill、Tekton、GitOps和Kubeflow部署机器学习产品的端到端示例。
问题
Kubeflow 是一个快速增长的开源项目,可以轻松在 Kubernetes 上部署和管理机器学习。
由于 Kubeflow 飞速普及,我们收到大量 GitHub Issue,这些 Issue 必须进行分类并分派给合适的主题专家。下表展示了过去一年新创建的 Issue 数量
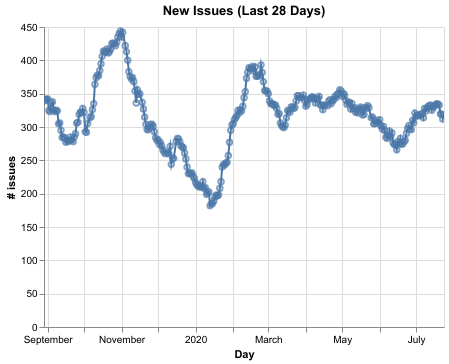
为了应对这种涌入,我们开始投入开发一个名为 Issue Label Bot 的 GitHub 应用,它使用机器学习来自动标注 Issue。我们的第一个模型是使用 GitHub 上一些流行的公共仓库集合进行训练的,并且只预测通用标签。随后,我们开始使用 Google AutoML 训练一个 Kubeflow 专用的模型。新模型能够以平均 72% 的精确率和平均 50% 的召回率预测 Kubeflow 专用标签。这大大减轻了 Kubeflow 维护者在 Issue 管理方面的繁重工作。下表包含在保留集上 Kubeflow 专用标签的评估指标。下面的精确率和召回率与我们根据需求校准的预测阈值相吻合。
| 标签 | 精确率 | 召回率 |
|---|---|---|
| area-backend | 0.6 | 0.4 |
| area-bootstrap | 0.3 | 0.1 |
| area-centraldashboard | 0.6 | 0.6 |
| area-components | 0.5 | 0.3 |
| area-docs | 0.8 | 0.7 |
| area-engprod | 0.8 | 0.5 |
| area-front-end | 0.7 | 0.5 |
| area-frontend | 0.7 | 0.4 |
| area-inference | 0.9 | 0.5 |
| area-jupyter | 0.9 | 0.7 |
| area-katib | 0.8 | 1.0 |
| area-kfctl | 0.8 | 0.7 |
| area-kustomize | 0.3 | 0.1 |
| area-operator | 0.8 | 0.7 |
| area-pipelines | 0.7 | 0.4 |
| area-samples | 0.5 | 0.5 |
| area-sdk | 0.7 | 0.4 |
| area-sdk-dsl | 0.6 | 0.4 |
| area-sdk-dsl-compiler | 0.6 | 0.4 |
| area-testing | 0.7 | 0.7 |
| area-tfjob | 0.4 | 0.4 |
| platform-aws | 0.8 | 0.5 |
| platform-gcp | 0.8 | 0.6 |
鉴于新 Issue 到来的速度,定期重新训练我们的模型成为首要任务。我们认为持续地重新训练和部署模型以利用这些新数据,对于保持模型有效性至关重要。
我们的解决方案
我们的 CI/CD 解决方案如图 2 所示。我们没有明确创建一个有向无环图(DAG)来连接 ML 工作流中的各个步骤(例如,预处理、训练、验证、部署等)。相反,我们使用一组独立的控制器。每个控制器声明式地描述世界的期望状态,并采取必要的行动使世界的实际状态与之匹配。这种独立性使我们可以轻松地为每个步骤使用最合适的工具。更具体地说,我们使用
- Jupyter notebook 用于开发模型。
- GitOps 用于持续集成和部署。
- Kubernetes 和托管云服务用于底层基础设施。
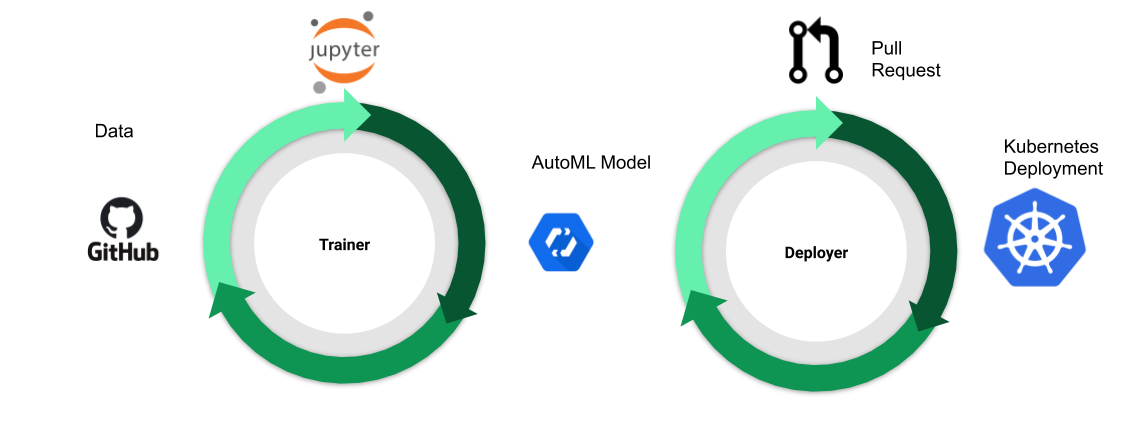
有关模型训练和部署的更多详细信息,请参阅下面的执行部分。
背景
使用 Reconcilers 构建弹性系统
Reconciler 是一种控制模式,已被证明对于构建弹性系统极其有用。协调(reconcile)模式是Kubernetes 工作原理的核心。图 3 说明了 Reconciler 的工作方式。Reconciler 首先通过观察世界的状态来工作;例如,当前部署的是什么模型。然后,Reconciler 将其与世界的期望状态进行比较并计算差异(diff);例如,标签为“version=20200724”的模型应该被部署,但当前部署的模型标签是“version=20200700”。接着,Reconciler 会采取必要的行动,将世界驱动到期望状态;例如,打开一个 Pull Request 来更改已部署的模型。
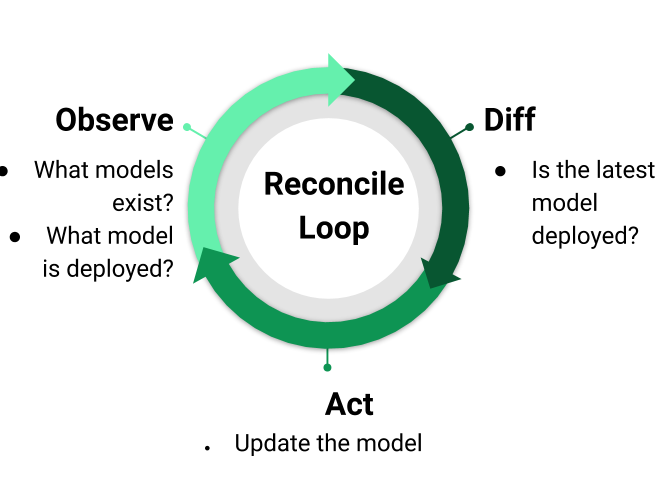
Reconcilers 已被证明对于构建弹性系统极其有用,因为一个良好实现的 Reconciler 提供了高度的信心,无论系统如何受到干扰,它最终都会回到期望的状态。
没有 DAG
控制器的声明式特性意味着数据可以流经一系列控制器,而无需明确创建 DAG。代替 DAG,一系列数据处理步骤可以表示为一组期望状态,如下面图 4 所示

这种基于 Reconciler 的范式相比许多传统的基于 DAG 的工作流具有以下优势
- 针对故障的弹性:系统持续寻求实现和维护期望状态。
- 工程团队自主性提高:每个团队都可以自由选择适合其需求的工具和基础设施。Reconciler 框架只需要控制器之间最小程度的耦合,同时仍允许编写富有表现力的工作流。
- 久经考验的模式和工具:这种基于 Reconciler 的框架并非创新。Kubernetes 拥有丰富的工具生态系统,旨在简化构建控制器。Kubernetes 的流行意味着存在一个庞大且不断增长的社区,熟悉这种模式及支持工具。
GitOps:通过 Pull Request 进行操作
GitOps(图 5)是一种管理基础设施的模式。GitOps 的核心思想是,源代码控制(不一定是 git)应该成为描述基础设施配置文件的单一事实来源。然后,控制器可以监控源代码控制,并在配置发生变化时自动更新您的基础设施。这意味着要进行更改(或撤销更改),您只需打开一个 Pull Request。
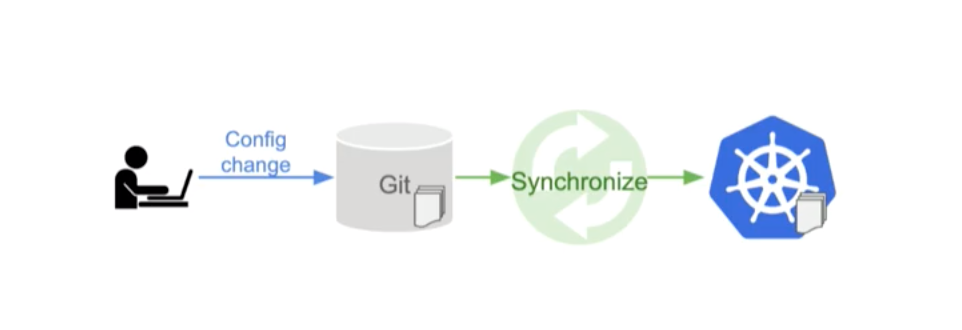
整合:Reconciler + GitOps = ML 的 CI/CD
有了这些背景知识,让我们深入探讨如何通过结合 Reconciler 和 GitOps 模式来构建 ML 的 CI/CD。
我们需要解决三个问题
- 如何计算世界的期望状态和实际状态之间的差异(diff)?
- 如何进行必要的更改以使实际状态与期望状态匹配?
- 如何构建一个控制回路来持续运行 1 和 2?
计算 Diff
为了计算差异,我们只需编写执行我们精确需求的 lambda 函数。在本例中,我们编写了两个 lambda 函数
我们将这些 lambda 函数封装在一个简单的 Web 服务器中,并部署在 Kubernetes 上。我们选择这种方法的一个原因是,我们希望依赖 Kubernetes 的 git-sync 将我们的仓库镜像到 Pod 卷中。这使得我们的 lambda 函数极其简单,因为所有的 Git 管理都由运行 git-sync 的 sidecar 容器负责处理。
执行
为了应用必要的更改,我们使用 Tekton 将我们用于执行各种步骤的各种 CLI 工具连接起来。
模型训练
为了训练我们的模型,我们有一个Tekton 任务,它负责
- 使用 papermill 运行我们的 notebook。
- 使用 nbconvert 将 notebook 转换为 html。
- 使用 gsutil 将
.ipynb和.html文件上传到 GCS。
这个 notebook 从 BigQuery 获取 GitHub Issue 数据,并在 GCS 上生成适合导入到 Google AutoML 的 CSV 文件。然后,这个 notebook 启动一个 AutoML 作业来训练模型。
我们选择 AutoML 是因为我们想专注于构建一个完整的端到端解决方案,而不是迭代模型本身。AutoML 提供了一个具有竞争力的基线,我们未来可能会尝试在此基础上进行改进。
为了方便查看执行后的 notebook,我们将其转换为 html 并上传到 GCS,这使得提供公共的静态内容变得容易。这使我们能够使用 notebook 生成丰富的可视化图表来评估我们的模型。
模型部署
为了部署我们的模型,我们有一个Tekton 任务,它负责
- 使用 kpt 更新我们的 ConfigMap 以包含期望的值。
- 运行 git 将我们的更改推送到一个分支。
- 使用围绕 GitHub CLI (gh) 的封装来创建一个 PR。
控制器确保在任何时候只有一个 Tekton 流水线在运行。我们将流水线配置为始终推送到同一个分支。这确保了我们只需要打开一个 PR 来更新模型,因为 GitHub 不允许从同一个分支创建多个 PR。
PR 合并后,Anthos Config Management 会自动将 Kubernetes 清单(manifests)应用到我们的 Kubernetes 集群。
为什么选择 Tekton
我们选择 Tekton 是因为我们面临的主要挑战是在各种容器中顺序运行一系列 CLI。Tekton 非常适合这一点。重要的是,Tekton 任务中的所有步骤都在同一个 Pod 上运行,这允许使用 Pod 卷在步骤之间共享数据。
此外,由于 Tekton 资源是 Kubernetes 资源,我们可以采用相同的 GitOps 模式和工具来更新我们的流水线定义。
控制回路
最后,我们需要构建一个控制回路,定期调用我们的 lambda 函数,并在需要时启动 Tekton 流水线。我们使用 kubebuilder 创建了一个简单的自定义控制器。我们控制器的协调(reconcile)循环将调用我们的 lambda 函数来确定是否需要同步以及同步所需的参数。如果需要同步,控制器会触发一个 Tekton 流水线来执行实际更新。我们的自定义资源示例如下
apiVersion: automl.cloudai.kubeflow.org/v1alpha1
kind: ModelSync
metadata:
name: modelsync-sample
namespace: label-bot-prod
spec:
failedPipelineRunsHistoryLimit: 10
needsSyncUrl: http://labelbot-diff.label-bot-prod/needsSync
parameters:
- needsSyncName: name
pipelineName: automl-model
pipelineRunTemplate:
spec:
params:
- name: automl-model
value: notavlidmodel
- name: branchName
value: auto-update
- name: fork
value: git@github.com:kubeflow/code-intelligence.git
- name: forkName
value: fork
pipelineRef:
name: update-model-pr
resources:
- name: repo
resourceSpec:
params:
- name: url
value: https://github.com/kubeflow/code-intelligence.git
- name: revision
value: master
type: git
serviceAccountName: auto-update
successfulPipelineRunsHistoryLimit: 10
自定义资源指定了用于计算是否需要同步的 lambda 函数的端点 needsSyncUrl,以及一个 Tekton PipelineRun 模板 pipelineRunTemplate,用于描述需要同步时创建的流水线运行。控制器负责处理细节;例如,确保每个资源一次只运行一个流水线,清理旧的运行等。所有繁重的工作都由 Kubernetes 和 kubebuilder 为我们处理了。
注意,出于历史原因,Kind ModelSync 和 apiVersion automl.cloudai.kubeflow.org 并不能反映控制器实际的功能。我们计划将来修复这个问题。
构建您自己的 CI/CD 流水线
我们的代码库距离成为完善、易于重用的工具还有很长的路要走。尽管如此,它都是公开的,可以作为您尝试构建自己的流水线的一个有用的起点。
以下是一些入门指导
- 使用 Dockerfile 构建您自己的ModelSync 控制器
- 修改 kustomize 包以使用您的镜像并部署控制器
- 根据您的用例需要,定义一个或多个 lambda 函数
- 您可以参考我们的Lambda 服务器作为示例
- 我们使用 Go 编写了我们的服务器,但您可以使用任何您喜欢的语言和 Web 框架(例如 Flask)
- 定义适合您的用例的 Tekton 流水线;我们的流水线(链接如下)可能是一个有用的起点
- Notebook Tekton 任务 - 使用 papermill 运行 notebook 并上传到 GCS
- PR Tekton 任务 - 用于创建 GitHub PR 的 Tekton 任务
- 为您的用例定义 ModelSync 资源;您可以参考我们的示例
- ModelSync 部署规范 - 用于持续部署 Label Bot 的 YAML
- ModelSync 训练规范 - 用于持续训练我们模型的 YAML
如果您希望看到我们清理代码并在未来的 Kubeflow 版本中包含它,请在 Issue kubeflow/kubeflow#5167 中发表意见。
后续工作
血缘追踪
由于我们的 CI/CD 流水线中没有表示步骤序列的显式 DAG,因此理解模型的血缘关系可能具有挑战性。幸运的是,Kubeflow Metadata 解决了这个问题,它使得每个步骤都可以轻松记录关于使用什么代码和输入产生了什么输出的信息。Kubeflow Metadata 可以轻松恢复和绘制血缘图。下图展示了我们 xgboost 示例的血缘图示例。
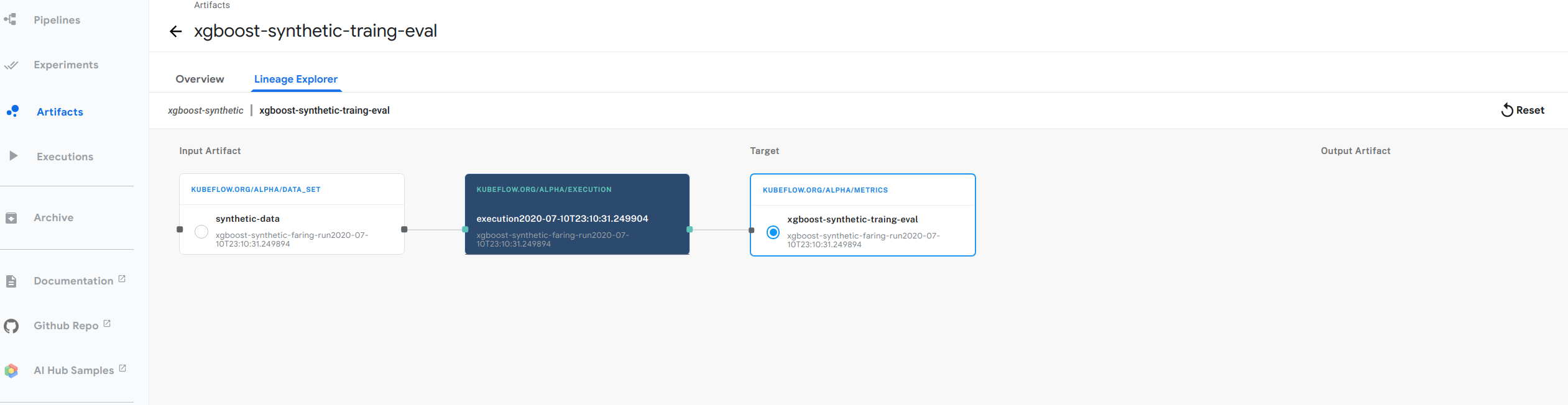
我们的计划是让控制器自动将血缘追踪信息写入元数据服务器,以便我们轻松了解生产环境中内容的血缘关系。
结论

构建 ML 产品是一项团队协作。为了将模型从概念验证阶段推进到最终产品,数据科学家和 DevOps 工程师需要协同合作。为了促进这种协作,我们认为重要的是允许数据科学家和 DevOps 工程师使用他们偏好的工具。具体来说,我们希望为数据科学家、DevOps 工程师和 SRE 提供以下工具支持
- Jupyter notebook 用于开发模型。
- GitOps 用于持续集成和部署。
- Kubernetes 和托管云服务用于底层基础设施。
为了最大化每个团队的自主性并减少对工具的依赖,我们的 CI/CD 流程采用去中心化的方法。我们的方法不是明确定义一个连接各个步骤的 DAG,而是依赖于一系列可以独立定义和管理的控制器。我们认为这很自然地适用于职责可能跨团队划分的企业;数据工程团队可能负责将网络日志转化为特征,建模团队可能负责从特征生成模型,而部署团队可能负责将这些模型推向生产环境。
延伸阅读
如果您想了解更多关于 GitOps 的信息,我们建议阅读 Weaveworks 的这篇指南。
要学习如何构建您自己的 Kubernetes 控制器,可以查阅kubebuilder 的书,其中包含一个端到端示例。