使用 Katib 优化 RAG 管线:超参数调优以获得更好的检索与生成
利用 Katib 实现高效的 RAG 优化。
引言
随着人工智能和机器学习模型变得越来越复杂,优化其性能仍然是一个关键挑战。Kubeflow 提供了一个强大的组件 Katib,专为超参数优化和神经架构搜索而设计。作为 Kubeflow 生态系统的一部分,Katib 支持对底层机器学习模型进行可扩展的自动化调优,减少参数选择所需的手动工作,同时提高跨不同 ML 工作流程的模型性能。
随着检索增强生成(RAG)成为一种越来越流行的提高搜索和检索质量的方法,优化其参数对于获得高质量结果至关重要。RAG 管线涉及多个超参数,这些参数影响检索准确性、减少幻觉和语言生成质量。在本博客中,我们将探讨如何利用 Katib 来微调 RAG 管线,通过系统地调整关键超参数来确保最佳性能。
开始吧!
步骤 1:设置
由于计算资源比完美标记的数据集更稀缺 :),我们将使用轻量级的 Kind 集群(Kubernetes in Docker)在本地运行此示例。请放心,通过增加数据集大小和要调优的超参数数量,此设置可以无缝扩展到更大的集群。
首先,按照文档中概述的步骤在我们的集群中安装 Katib 控制平面。
步骤 2:实现 RAG 管线
在此实现中,我们使用检索器模型(它将查询和文档编码为向量表示以找到最相关的匹配项)来根据查询获取相关文档,并使用生成器模型生成连贯的文本响应。
实现细节
- 检索器:Sentence Transformer 与 FAISS (Facebook AI Similarity Search) 索引
- SentenceTransformer 模型 (paraphrase-MiniLM-L6-v2) 将预定义文档编码为向量表示。
- FAISS 用于索引这些文档嵌入并执行高效的相似性搜索以检索最相关的文档。
- 生成器:预训练的 GPT-2 模型
- 使用 Hugging Face GPT-2 文本生成管线(可以用任何其他模型替换)根据检索到的文档生成响应。我选择 GPT-2 作为此示例,因为它足够轻量化,可以在我的本地机器上运行,同时仍能生成连贯的响应。
- 查询处理与响应生成
- 提交查询后,检索器对其进行编码,并在 FAISS 索引中搜索 top-k 个最相似的文档。
- 将这些检索到的文档连接起来形成输入上下文,然后将其传递给 GPT-2 模型以生成响应。
- 评估:BLEU(双语评估替补)得分计算
- 为了评估生成的响应质量,我们使用 BLEU 分数,这是一个用于评估文本生成的常用指标。
- evaluate 函数接受一个查询,检索文档,生成响应,并将其与一个基本事实参考进行比较,以使用 nltk 库的平滑函数计算 BLEU 分数。
为了运行 Katib,我们将使用 Katib SDK,它提供了用于在 Kubeflow 中定义和运行超参数调优实验的程序化接口。
Katib 需要一个目标函数,它
- 定义我们要优化的目标(例如,用于文本生成质量的 BLEU 分数)。
- 使用不同的超参数值执行 RAG 管线。
- 返回一个评估指标,以便 Katib 可以比较不同的超参数配置。
def objective(parameters):
# Import dependencies inside the function (required for Katib)
import numpy as np
import faiss
from sentence_transformers import SentenceTransformer
from transformers import pipeline
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
# Function to fetch documents (Modify as needed)
def fetch_documents():
"""Returns a predefined list of documents or loads them from a file."""
return [
...
]
# OR, to load from a file:
# with open("/path/to/documents.json", "r") as f:
# return json.load(f)
# Define the RAG pipeline within the function
def rag_pipeline_execute(query, top_k, temperature):
"""Retrieves relevant documents and generates a response using GPT-2."""
# Initialize retriever
retriever_model = SentenceTransformer("paraphrase-MiniLM-L6-v2")
# Sample documents
documents = fetch_documents()
# Encode documents
doc_embeddings = retriever_model.encode(documents)
index = faiss.IndexFlatL2(doc_embeddings.shape[1])
index.add(np.array(doc_embeddings))
# Encode query and retrieve top-k documents
query_embedding = retriever_model.encode([query])
distances, indices = index.search(query_embedding, top_k)
retrieved_docs = [documents[i] for i in indices[0]]
# Generate response using GPT-2
generator = pipeline("text-generation", model="gpt2", tokenizer="gpt2")
context = " ".join(retrieved_docs)
generated = generator(context, max_length=50, temperature=temperature, num_return_sequences=1)
return generated[0]["generated_text"]
# TODO: Provide queries and ground truth directly here or load them dynamically from a file/external volume.
query = "" # Example: "Tell me about the Eiffel Tower."
ground_truth = "" # Example: "The Eiffel Tower is a famous landmark in Paris."
# Extract hyperparameters
top_k = int(parameters["top_k"])
temperature = float(parameters["temperature"])
# Generate response
response = rag_pipeline_execute(query, top_k, temperature)
# Compute BLEU score
reference = [ground_truth.split()] # Tokenized reference
candidate = response.split() # Tokenized candidate response
smoothie = SmoothingFunction().method1
bleu_score = sentence_bleu(reference, candidate, smoothing_function=smoothie)
# Print BLEU score in Katib-compatible format
print(f"BLEU={bleu_score}")
注意:请确保以 <参数>=<值> 的格式返回结果,以便 Katib 的指标收集器能够使用它。在 Katib 指标收集器指南中提供了更多配置输出的方法。
步骤 3:运行 Katib 实验
一旦我们的管线被封装在目标函数中,我们就可以配置 Katib 通过调优超参数来优化 BLEU 分数
-
top_k:检索到的文档数量(例如,介于 10 到 20 之间)。 -
temperature:文本生成的随机性(例如,介于 0.5 到 1.0 之间)。
定义超参数搜索空间
parameters = {
"top_k": katib.search.int(min=10, max=20),
"temperature": katib.search.double(min=0.5, max=1.0, step=0.1)
}
让我们提交实验吧!我们将使用 tune API,它将运行多个试验来为我们的 RAG 管线找到最优的 top_k 和 temperature 值。
katib_client = katib.KatibClient(namespace="kubeflow")
name = "rag-tuning-experiment"
katib_client.tune(
name=name,
objective=objective,
parameters=parameters,
algorithm_name="grid", # Grid search for hyperparameter tuning
objective_metric_name="BLEU",
objective_type="maximize",
objective_goal=0.8,
max_trial_count=10, # Run up to 10 trials
parallel_trial_count=2, # Run 2 trials in parallel
resources_per_trial={"cpu": "1", "memory": "2Gi"},
base_image="python:3.10-slim",
packages_to_install=[
"transformers==4.36.0",
"sentence-transformers==2.2.2",
"faiss-cpu==1.7.4",
"numpy==1.23.5",
"huggingface_hub==0.20.0",
"nltk==3.9.1"
]
)
提交实验后,我们可以看到表明 Katib 已开始试验的输出
Experiment Trials status: 0 Trials, 0 Pending Trials, 0 Running Trials, 0 Succeeded Trials, 0 Failed Trials, 0 EarlyStopped Trials, 0 MetricsUnavailable Trials
Current Optimal Trial:
{'best_trial_name': None,
'observation': {'metrics': None},
'parameter_assignments': None}
Experiment conditions:
[{'last_transition_time': datetime.datetime(2025, 3, 13, 19, 40, 32, tzinfo=tzutc()),
'last_update_time': datetime.datetime(2025, 3, 13, 19, 40, 32, tzinfo=tzutc()),
'message': 'Experiment is created',
'reason': 'ExperimentCreated',
'status': 'True',
'type': 'Created'}]
Waiting for Experiment: kubeflow/rag-tuning-experiment to reach Succeeded condition
.....
Experiment Trials status: 9 Trials, 0 Pending Trials, 2 Running Trials, 7 Succeeded Trials, 0 Failed Trials, 0 EarlyStopped Trials, 0 MetricsUnavailable Trials
Current Optimal Trial:
{'best_trial_name': 'rag-tuning-experiment-66tmh9g7',
'observation': {'metrics': [{'latest': '0.047040418725887996',
'max': '0.047040418725887996',
'min': '0.047040418725887996',
'name': 'BLEU'}]},
'parameter_assignments': [{'name': 'top_k', 'value': '10'},
{'name': 'temperature', 'value': '0.6'}]}
Experiment conditions:
[{'last_transition_time': datetime.datetime(2025, 3, 13, 19, 40, 32, tzinfo=tzutc()),
'last_update_time': datetime.datetime(2025, 3, 13, 19, 40, 32, tzinfo=tzutc()),
'message': 'Experiment is created',
'reason': 'ExperimentCreated',
'status': 'True',
'type': 'Created'}, {'last_transition_time': datetime.datetime(2025, 3, 13, 19, 40, 52, tzinfo=tzutc()),
'last_update_time': datetime.datetime(2025, 3, 13, 19, 40, 52, tzinfo=tzutc()),
'message': 'Experiment is running',
'reason': 'ExperimentRunning',
'status': 'True',
'type': 'Running'}]
Waiting for Experiment: kubeflow/rag-tuning-experiment to reach Succeeded condition
我们还可以看到正在运行的实验和试验,以搜索最优参数
kubectl get experiments.kubeflow.org -n kubeflow
NAME TYPE STATUS AGE
rag-tuning-experiment Running True 10m
kubectl get trials --all-namespaces
NAMESPACE NAME TYPE STATUS AGE
kubeflow rag-tuning-experiment-7wskq9b9 Running True 10m
kubeflow rag-tuning-experiment-cll6bt4z Running True 10m
kubeflow rag-tuning-experiment-hzxrzq2t Running True 10m
已完成的试验及其结果将如下所示在 UI 中显示。访问 Katib UI 的步骤可在文档中找到

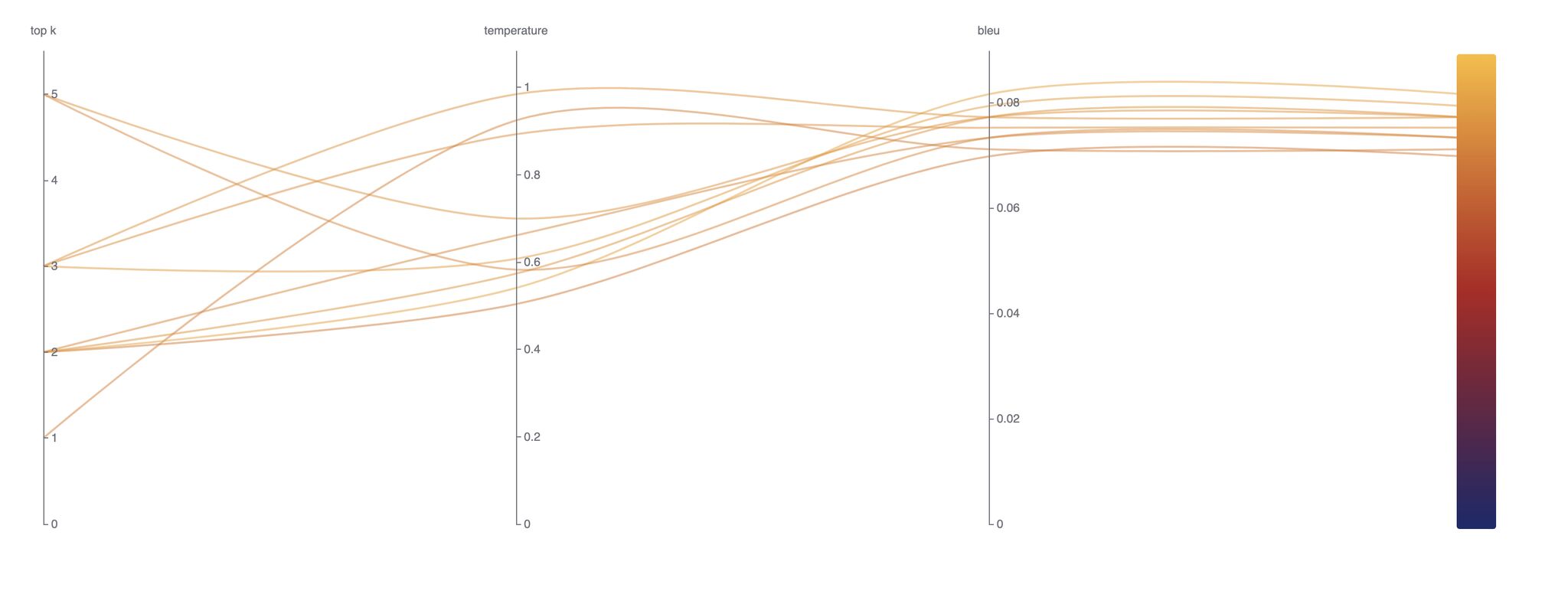
结论
在本实验中,我们利用 Kubeflow Katib 优化了检索增强生成 (RAG) 管线,系统地调优了 top_k 和 temperature 等关键超参数,以提高检索精度和生成响应的质量。
对于任何从事 RAG 系统或超参数优化工作的人来说,Katib 都是一个强大的工具——它能够对机器学习模型进行可扩展、高效和智能的调优!我们希望本教程能帮助您简化超参数调优流程,并在您的 ML 工作流程中释放新的效率!