LLM 超参数优化 API:我的 Google Summer of Code Kubeflow 之旅
今年夏天,我有幸参加了 Google Summer of Code (GSoC) 项目,并为开源机器学习工具包 Kubeflow 做出了贡献。我的项目重点是在 Kubeflow 的自动化超参数调优系统 Katib 中,为大型语言模型 (LLM) 的超参数优化开发一个高级 API。我想与对 Kubeflow、GSoC 或 LLM 优化感兴趣的人分享这次经历中的心得体会。
动机
GPT 和 BERT 等 LLM 的快速发展和日益普及,催生了对 Kubernetes 中高效 LLMOps 的日益增长的需求。为了解决这个问题,我们在 Training Python SDK 中开发了一个 训练 API,该 API 利用分布式 PyTorchJob worker 简化了 LLM 的微调过程。然而,超参数优化仍然是提升模型性能的关键但劳动密集型任务。
目标
超参数优化至关重要,但非常耗时,特别是对于拥有数十亿参数的 LLM 而言。这个 API 通过处理 Kubernetes 基础设施来简化流程,让数据科学家能够专注于模型性能,而不是系统配置。
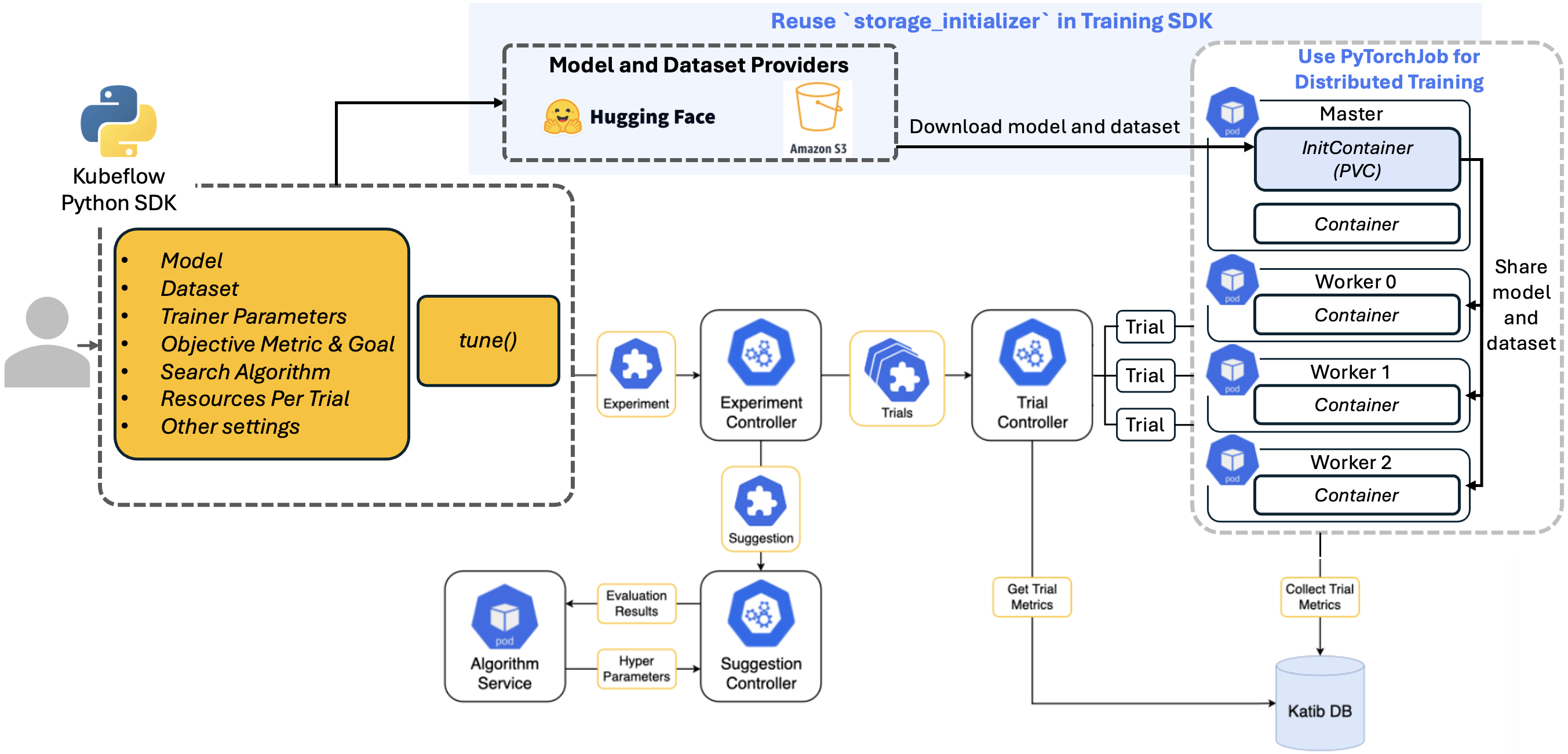
借助这个 API,用户可以从 Hugging Face 和 Amazon S3 导入预训练模型和数据集,定义参数,包括超参数搜索空间、优化目标和资源配置。然后,该 API 会自动创建 Experiment,Experiment 中包含多个使用 PyTorch 分布式训练、具有不同超参数设置的 Trial。接着,它会收集和分析每个 Trial 的指标,以确定最佳超参数配置。
有关使用此 API 的详细说明,请参阅此指南
我对 GSoC 项目的贡献
我的项目工作大致可以分为四个阶段
- 阶段 1:设计 API,起草项目提案,并将其完善为 Kubeflow 增强提案 (KEP)。
- 阶段 2:开发和实现高级 API。
- 阶段 3:实现 API 的单元测试和端到端测试。
- 阶段 4:创建文档并将工作成果展示给 Kubeflow 社区。
此外,我解决了之前 Katib 和 Training Operator 版本中的几个关键错误,并贡献了一些新功能,例如为训练 API 编写端到端测试。
如果您有兴趣,这里是我在整个过程中提交的所有 pull request 的详细总结。
经验教训
这是我第一次参与开源项目,在整个项目过程中,我学到了很多技术知识,包括 Docker、Kubernetes 和 Kubeflow 本身。在开发和实现 API 之前,我投入了大量时间来熟悉和适应 Kubeflow。官方文档和GitHub 仓库在此过程中是无价的资源。
除了这些技术技能之外,我还学到了一些关键的经验教训,这些经验教训有助于个人和职业上的更广泛成长。
从用户的角度思考
一个关键的教训是考虑用户需求的重要性。与导师讨论 API 设计时,我学会了关注用户需要什么功能以及他们喜欢如何使用这些功能。倾听用户反馈对于有效的产品设计至关重要。
不要害怕 Bug
过去,我常常对 Bug 感到不知所措,不知道如何解决它们。当一个 Bug 导致 Katib trial 中的容器失败时,我的导师引导我完成了调试过程,教会我如何系统地追踪和理解问题。关键在于有条不紊地进行调试,并仔细思考问题的每一个步骤。
沟通很重要
沟通在协作中非常重要,尤其是在开源项目中。在开源项目中有多种沟通方式,例如 GitHub issues 或 PR、Slack 以及社区会议。我也很感谢我的导师在每周例会中与我讨论我遇到的挑战,并提供了宝贵的指导。
每一份贡献都弥足珍贵
最初,我以为为开源做贡献很复杂。我认识到,每一份贡献,无论多么微小,都是有价值并受到赞赏的。例如,贡献文档至关重要,特别是对于新手而言。
结语
我非常感谢在整个项目过程中支持我的每个人。你们的建议、忠告和鼓励对于我完成工作是无价的。
我特别要向我的导师 Andrey Velichkevich 致以衷心的感谢。他对项目和行业都拥有深厚的知识,再加上他乐于助人的精神,给我带来了巨大的启发。我非常感谢他投入时间和精力指导我,从 API 的高层设计到代码格式等细微之处。我从他的指导中学到了很多。
展望未来,我很高兴能继续为 Kubeflow 做贡献。我也期待通过改进文档和与社区的新手分享我的经验来帮助未来的贡献者。
如果您对开源感兴趣并想加入 Kubeflow,GSoC 2025 申请现已开放!在这里查看详情——我们非常欢迎您的加入!